
Na CES 2026 NVIDIA ogłosiła to, co może być najbardziej znaczącą publikacją open-source w dziedzinie AI do tej pory. Firma zaprezentowała nowe modele, zbiory danych i narzędzia obejmujące wszystko, od rozpoznawania mowy po odkrywanie leków.
Skala jest imponująca:
- 10 bilionów tokenów do trenowania językowego
- 500 000 trajektorii robotycznych
- 455 000 struktur białek
- 100 terabajtów danych z czujników pojazdów
Duże firmy, w tym Bosch, Salesforce, Uber, Palantir i CrowdStrike, już budują na tych technologiach.
Nemotron RAG: inteligentniejsze wyszukiwanie dokumentów

Model Embedding: Llama-Nemotron-Embed-VL-1B-V2 (1,7B parametrów) Model Reranking: Llama-Nemotron-Rerank-VL-1B-V2 (1,7B parametrów) Również dostępny: 8B-parametrowy model embedding tylko tekstowy Długość kontekstu: Do 8192 tokenów Licencja: Dozwolone użycie komercyjne
Znajdowanie informacji ukrytych w dokumentach to codzienna walka pracowników wiedzy. Nemotron RAG wprowadza multimodalną inteligencję do wyszukiwania dokumentów, przetwarzając zarówno tekst, jak i obrazy z dokładnymi wielojęzykowymi analizami w 26 językach.
Jak to działa
Pipeline Nemotron RAG łączy trzy komponenty:
- Model Embedding: przekształca dokumenty w reprezentacje wektorowe do przechowywania i wyszukiwania
- Model Reranking: przenosi potencjalnych kandydatów do ostatecznej kolejności za pomocą cross-attention
- Model Reasoning: generuje dokładne odpowiedzi na podstawie pobranego kontekstu
Przykład z życia: Agent IT Help Desk
NVIDIA zademonstrowa, jak te modele współpracują w agencie IT Help Desk:
- Nemotron Nano 9B V2: główny model reasoning do generowania odpowiedzi
- Llama 3.2 EmbedQA 1B V2: przekształca dokumenty w wektorowe osadzenia
- Llama 3.2 RerankQA 1B V2: ponownie rankinguje pobrane dokumenty pod kątem trafności
Te modele wspólnie umożliwiają agentowi dokładne odpowiadanie na zapytania użytkowników, wykorzystując generowanie języka, pobieranie dokumentów i możliwości rerankingu.
Kto tego używa
Cadence modeluje zasoby projektowe logiki, takie jak dokumenty mikroarchitektury, ograniczenia i materiał weryfikacyjny. Inżynierowie mogą zadawać pytania typu "Chcę rozszerzyć kontroler przerwan o obsługę trybu niskiego poboru mocy, pokaż mi, które sekcje specyfikacji wymagają zmian" i natychmiast znaleźć odpowiednie wymagania.
IBM testuje te modele w celu poprawy wyszukiwania i wnioskowania w dokumentacji technicznej.
Nemotron Speech: rozmawiaj ze swoimi urządzeniami jak nigdy dotąd
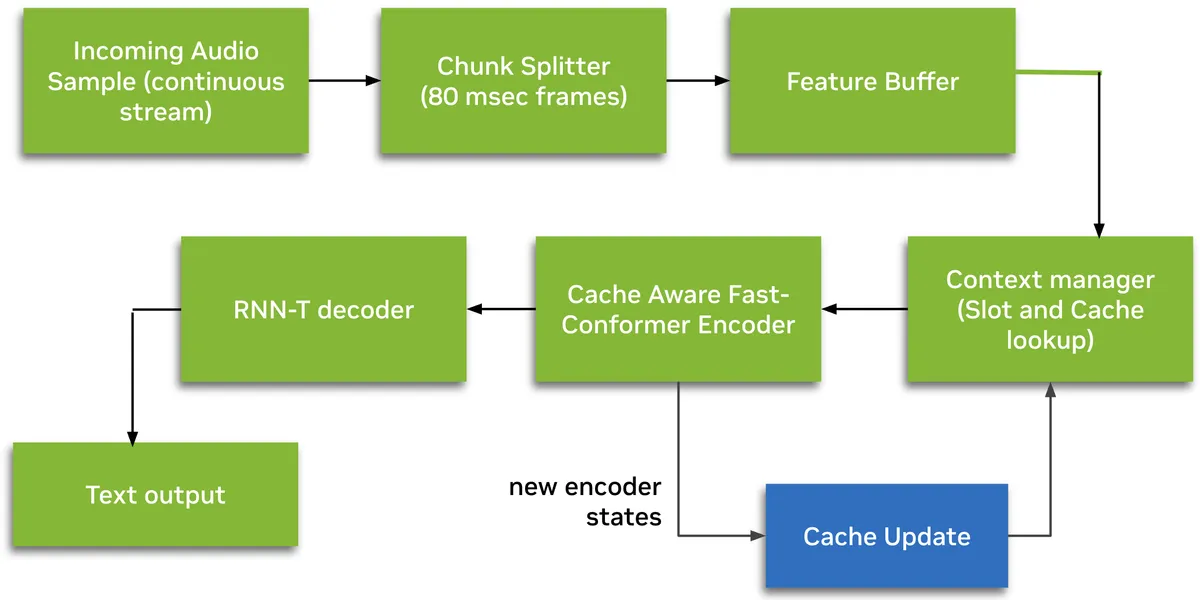
Model: Nemotron-Speech-Streaming-En-0.6B Parametry: 600M Architektura: Cache-aware FastConformer encoder + dekoder RNN-T Opóźnienie: Streaming poniżej 100ms Licencja: Dozwolone użycie komercyjne
Nemotron Speech zapewnia rozpoznawanie mowy w czasie rzeczywistym, które działa 10x szybciej niż porównywalne modele i prowadzi w aktualnych rankingach ASR.
Kluczowe cechy
- Architektura strumieniowa cache-aware: przetwarza tylko nowe fragmenty audio, wykorzystując zapisany kontekst encodera
- Konfigurowane w czasie wykonywania tryby opóźnienia: fragmenty 80ms, 160ms, 560ms lub 1,12s bez ponownego trenowania
- Natywna obsługa interpunkcji i wielkich liter
- Trenowany na 285 000 godzinach danych audio z zestawu danych NVIDIA Granary
Kto tego używa
Bosch już używa Nemotron Speech, aby umożliwić kierowcom interakcje z pojazdami za pomocą poleceń głosowych. ServiceNow trenuje swoją rodzinę modeli Apriel na zestawach danych Nemotron, uzyskując wydajną multimodalną wydajność.
Spodziewaj się tej technologii w urządzeniach smart home, systemach obsługi klienta i narzędziach dostępności w całym 2026 roku.
Clara: szybsze odkrywanie leków i lepsza opieka zdrowotna

La-Proteina: Projektowanie białek na poziomie atomów ReaSyn v2: Wykonalność syntezy leków KERMT: Komputerowe testy bezpieczeństwa RNAPro: Przewidywanie kształtu 3D RNA Zestaw danych: 455 000 syntetycznych struktur białek
Nowe modele Clara AI od NVIDIA mają na celu zmniejszenie przepaści między cyfrowym odkrywaniem a medycyną w świecie rzeczywistym. Nie będziesz bezpośrednio korzystać z tych modeli, ale mogą one znacząco wpłynąć na Twoją opiekę zdrowotną.
Przegląd modeli
| Model | Funkcja | Wpływ |
|---|---|---|
| La-Proteina | Projektowanie dużych, dokładnych na poziomie atomów białek | Badanie wcześniej nieuleczalnych chorób |
| ReaSyn v2 | Włączanie wykonalności syntezy do procesu odkrywania | Zapobieganie marnowaniu badań nad niepraktycznymi związkami |
| KERMT | Przewidywanie interakcji lek-organizm | Wykrywanie problemów przed kosztownymi badaniami klinicznymi |
| RNAPro | Przewidywanie kształtów 3D RNA | Umożliwienie spersonalizowanych terapii opartych na RNA |
Podsumowanie: Leczenie może dotrzeć do pacjentów szybciej i taniej.
Alpamayo: uczynienie samochodów autonomicznych mądrzejszymi

Model: Alpamayo-R1-10B Parametry: 10 miliardów (8,2B Cosmos Reason backbone + 2,3B action expert) Dane treningowe: 1+ miliard obrazów z 80 000 godzin jazdy z wielu kamer Zestaw danych: 1700+ godzin danych jazdy z 25 krajów Licencja: Niekomercyjna (badawcza)
Nowa rodzina Alpamayo od NVIDIA przyspieszy drogę do prawdziwie autonomicznych pojazdów. To pierwszy w branży otwarty model reasoning VLA zaprojektowany do jazdy autonomicznej.
Kluczowa innowacja: Chain-of-Thought Reasoning
W przeciwieństwie do tradycyjnych systemów AV, które jedynie wykrywają obiekty i planują trasy, Alpamayo wykorzystuje chain-of-thought reasoning. Może:
- Przetwarzać wideo z wielu kamer
- Generować trajektorie jazdy
- Wyjaśnić logikę stojącą za każdą decyzją
Przykładowe wyjście: "Przesuń się w lewo, aby zwiększyć odstęp od stożków budowlanych wchodzących na pas ruchu"
Co jest w zestawie
- Alpamayo 1: model reasoning VLA 10B na Hugging Face
- AlpaSim: otwartoźródłowy framework symulacji end-to-end
- Physical AI Open Datasets: 1700+ godzin pokrywających rzadkie przypadki brzegowe z 25 krajów i 2500+ miast
Kto tego używa
Lucid Motors, JLR, Uber i Berkeley DeepDrive używają Alpamayo do tworzenia reasoning-based AV stacków dla autonomii poziomu 4.
Cosmos: uczenie robotów rozumienia fizycznego świata

Cosmos Reason 2: wersje 2B i 8B parametrów Okno kontekstu: 256K tokenów (16x większe niż v1) Architektura: Oparta na Qwen3-VL Licencja: Dozwolone użycie komercyjne (NVIDIA Open Model License)
Na Hugging Face robotyka stała się najszybciej rosnącym segmentem, a modele NVIDIA prowadzą w liczbie pobrań.
Rodzina modeli Cosmos
| Model | Parametry | Funkcja |
|---|---|---|
| Cosmos Reason 2 | 2B / 8B | Physical AI reasoning VLM dla robotów i agentów AI |
| Cosmos Transfer 2.5 | - | Transfer stylu z wideo do świata |
| Cosmos Predict 2.5 | 2B / 14B | Przewidywanie przyszłego stanu jako wideo |
Kluczowe cechy Cosmos Reason 2
- Ulepszone rozumienie przestrzenno-czasowe z precyzją znaczników czasowych
- Lokalizacja punktów 2D/3D i współrzędne bounding box
- Wyjście danych trajektorii do sterowania robotem
- Obsługa OCR do odczytywania tekstu w środowisku
- Chain-of-thought reasoning z tagami
<think>
Isaac GR00T N1.6: model bazowy robota humanoidalnego
Parametry: 3B Bazowy VLM: wariant Cosmos-Reason-2B Architektura: VLA z 32-warstwowym transformerem dyfuzyjnym
GR00T N1.6 to otwarty model vision-language-action stworzony specjalnie dla robotów humanoidalnych. Odblokowuje pełną kontrolę ciała i wykorzystuje Cosmos Reason do lepszego rozumienia kontekstowego.
Kto tego używa
- Franka Robotics, Humanoid i NEURA Robotics - symulują, trenują i walidują zachowania robotów
- Salesforce, Hitachi, Uber i VAST Data - monitorowanie ruchu i produktywność w miejscu pracy
- Milestone - agenci AI wizji dla bezpieczeństwa publicznego
Nemotron Safety: budowanie wiarygodnej AI

Bezpieczeństwo treści: Llama-3.1-Nemotron-Safety-Guard-8B-v3 Wykrywanie PII: Nemotron-PII (oparty na GLiNER) Licencja: Dozwolone użycie komercyjne
Dla firm wdrażających AI, Nemotron Safety obejmuje modele bezpieczeństwa treści i wykrywanie PII z wysoką dokładnością.
Komponenty
- Model bezpieczeństwa treści: rozszerzona obsługa wielojęzyczna z niuansami kulturowymi
- Wykrywanie PII: wykrywa wrażliwe dane osobowe zanim wyciekną
- Kontrola tematów: zarządza, jakie tematy AI może omawiać
Kto tego używa
- CrowdStrike, Cohesity i Fortinet: wzmacniają bezpieczeństwo aplikacji AI
- CodeRabbit: napędza przeglądy kodu AI z ulepszoną szybkością i dokładnością
- Palantir: integracja z frameworkiem Ontology dla wyspecjalizowanych agentów AI
Co to oznacza dla wszystkich
Wszystkie modele i dane są dostępne teraz na GitHub i Hugging Face, także jako NVIDIA NIM microservices do skalowalnego wdrażania.
Podsumowanie otwartych danych
| Zestaw danych | Rozmiar | Zawartość |
|---|---|---|
| Tokeny językowe | 10 bilionów | Wielojęzyczne wnioskowanie, kodowanie, bezpieczeństwo |
| Trajektorie robotyczne | 500 000 | Ruch i manipulacja robotów |
| Struktury białek | 455 000 | Struktury syntetyczne dla biomedycznej AI |
| Dane czujników pojazdów | 100 TB | Różnorodne warunki jazdy |
| Wideo jazdy | 1700+ godzin | Rzadkie przypadki brzegowe z 25 krajów |
Linki na początek
- Modele Nemotron: developer.nvidia.com/nemotron
- Modele Cosmos: github.com/nvidia-cosmos
- Alpamayo: developer.nvidia.com/drive/alpamayo
- Isaac GR00T: developer.nvidia.com/isaac/gr00t
Dla zwykłych użytkowników ta publikacja oznacza lepszych asystentów głosowych, mądrzejsze wyszukiwanie dokumentów, szybsze opracowywanie leków, bezpieczniejsze samochody autonomiczne i bardziej zdolne roboty. Te technologie będą przenikać do produktów konsumenckich w całym 2026 roku.
NVIDIA stawia na to, że umożliwiając rozwój całego ekosystemu AI, sprzeda więcej GPU. Biorąc pod uwagę firmy już adoptujące te technologie, ten zakład się opłaca.
