

OpenAI wydaje GPT-5.2: Pierwszą sztuczną inteligencję przewyższającą profesjonalistów branżowych
OpenAI właśnie wypuściło GPT-5.2, a wyniki testów są absolutnie szalone. To nie jest kolejna przyrostowa aktualizacja. Po raz pierwszy w historii model AI konsekwentnie pokonuje ludzkich profesjonalistów branżowych w rzeczywistej pracy intelektualnej.
Testy porównawcze mówią same za siebie
| Test porównawczy | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Praca intelektualna) | 70,9% | 38,8% |
| SWE-Bench Pro (Inżynieria oprogramowania) | 55,6% | 50,8% |
| SWE-Bench Verified (Inżynieria oprogramowania) | 80,0% | 76,3% |
| GPQA Diamond (Pytania naukowe) | 92,4% | 88,1% |
| CharXiv Reasoning (Wykresy naukowe) | 88,7% | 80,3% |
| AIME 2025 (Matematyka konkursowa) | 100,0% | 94,0% |
| FrontierMath Tier 1-3 (Matematyka zaawansowana) | 40,3% | 31,0% |
| FrontierMath Tier 4 (Matematyka zaawansowana) | 14,6% | 12,5% |
| ARC-AGI-1 (Rozumowanie abstrakcyjne) | 86,2% | 72,8% |
| ARC-AGI-2 (Rozumowanie abstrakcyjne) | 52,9% | 17,6% |
Spójrzcie na ten skok w ARC-AGI-2. Z 17,6% do 52,9%. To 3-krotna poprawa w autentycznej zdolności rozumowania abstrakcyjnego w jednej generacji.
Liczba, która ma największe znaczenie
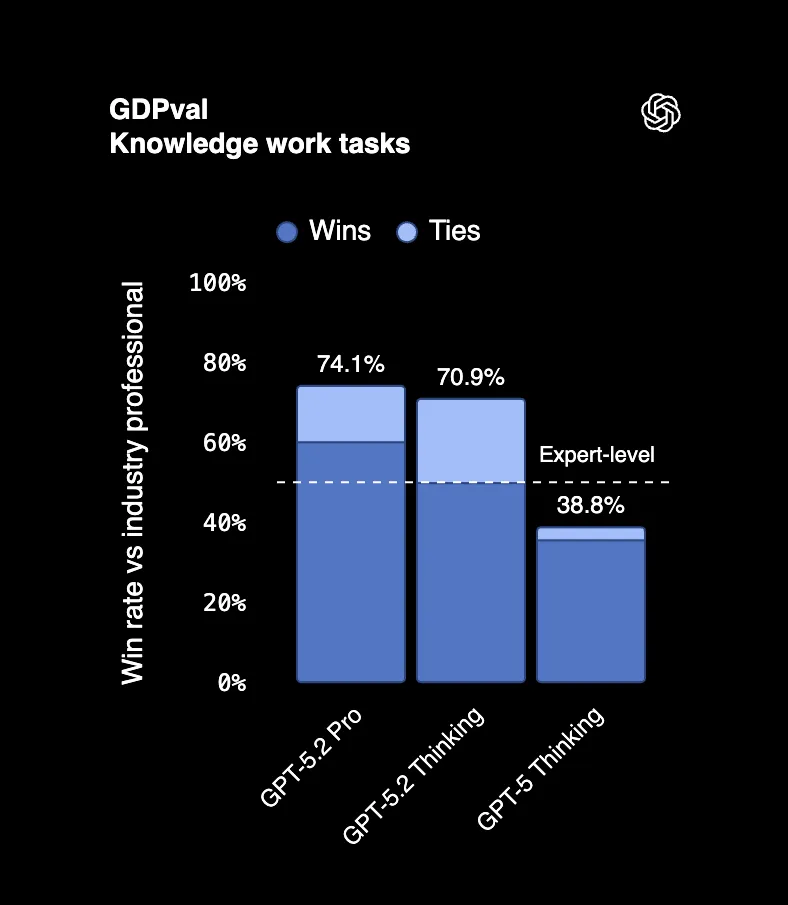
W teście GDPval, który mierzy rzeczywiste zadania profesjonalne w 44 zawodach, GPT-5.2 Thinking pokonuje lub remisuje z czołowymi profesjonalistami branżowymi w 70,9% przypadków. Mówimy o tworzeniu prezentacji, budowaniu arkuszy kalkulacyjnych, pisaniu raportów, rzeczach, za które ludzie dostają sześciocyfrowe pensje.
Jeden z sędziów oceniających wyniki powiedział, że "wygląda to, jakby zostało wykonane przez profesjonalną firmę z personelem". To nie jest pomyłka. Wynik AI został wzięty za pracę całego zespołu.
A oto wisienka na torcie: GPT-5.2 wygenerował te wyniki 11 razy szybciej i za mniej niż 1% kosztu pracy profesjonalnych ekspertów.
100% w matematyce konkursowej
GPT-5.2 Thinking zdobył 100% w AIME 2025, prestiżowym konkursie matematycznym, który wprawia w zakłopotanie większość ludzi. Nie 99%. Nie 98%. Perfekcyjny wynik.
W FrontierMath, który testuje matematykę na poziomie eksperckim, z którą borykają się nawet doktorzy matematyki, osiągnął 40,3%, w porównaniu z 31% w GPT-5.1.
Programowanie właśnie stało się poważne
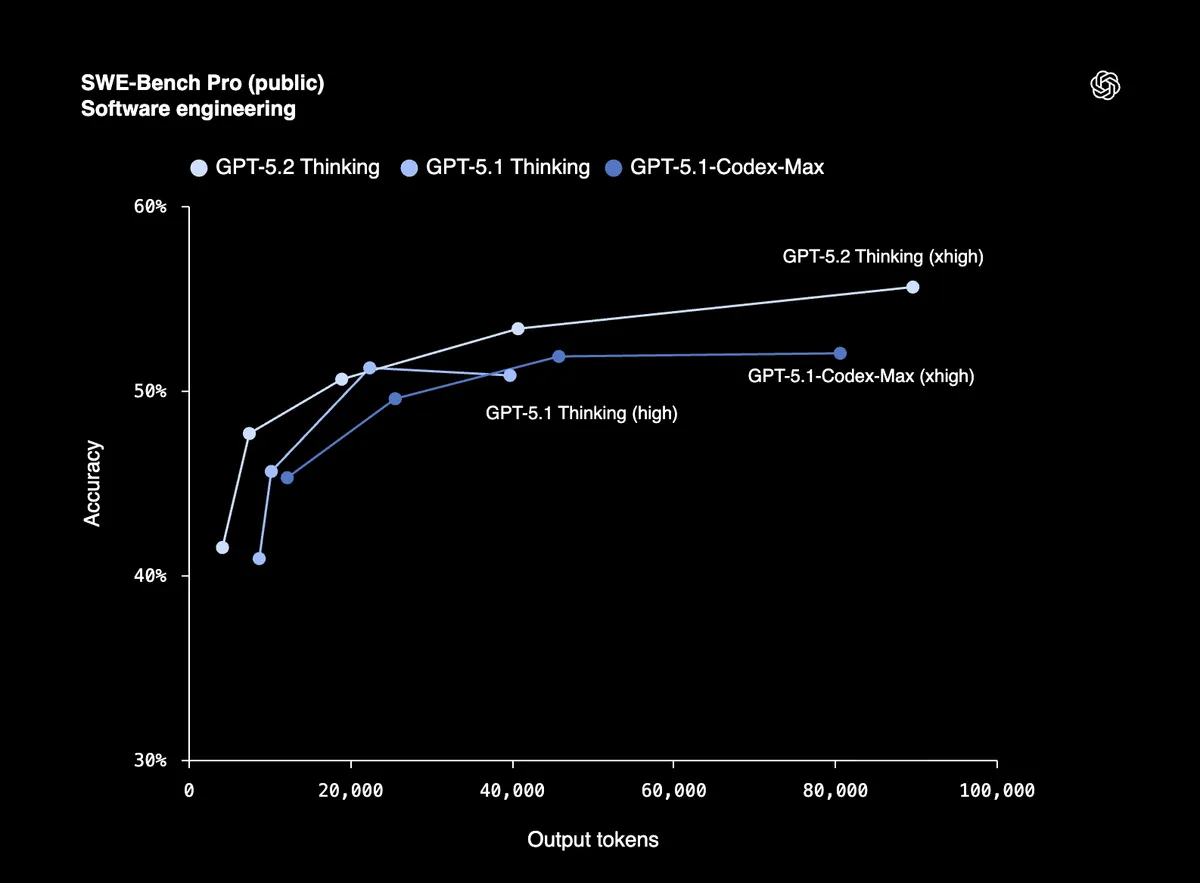
Wynik 80% w SWE-Bench Verified oznacza, że GPT-5.2 może niezawodnie debugować kod produkcyjny, implementować funkcje i refaktoryzować duże bazy kodu przy minimalnym nadzorze. SWE-Bench Pro testuje rzeczywistą inżynierię oprogramowania w czterech językach programowania, nie tylko w Pythonie.
Wcześni testerzy z Windsurf, JetBrains i Warp nazywają to "największym skokiem dla modeli GPT w kodowaniu agentowym od czasu GPT-5".
30% mniej halucynacji
To ma znaczenie dla każdego, kto używa AI profesjonalnie. GPT-5.2 Thinking generuje 30% mniej odpowiedzi z błędami w porównaniu z GPT-5.1. Dla badań, analiz i podejmowania decyzji to ogromny wzrost niezawodności.
Przełom w długim kontekście
GPT-5.2 jest pierwszym modelem, który osiąga niemal 100% dokładności w zadaniach z długim kontekstem do 256 tys. tokenów. Oznacza to, że możesz wrzucić do niego całe bazy kodu, kontrakty, prace naukowe lub transkrypcje, a on faktycznie utrzyma spójność w całym materiale.
Poprzednie modele traciły wątek w połowie. GPT-5.2 tego nie robi.
Wizja, która faktycznie działa
Wskaźniki błędów w rozumowaniu wykresów i zrozumieniu interfejsów oprogramowania zostały zmniejszone mniej więcej o połowę. Model może teraz dokładnie interpretować dashboardy, diagramy techniczne i zrzuty ekranu, co czyni go naprawdę użytecznym w zadaniach analizy wizualnej.

Co to oznacza dla Ciebie
Jeśli już płacisz za ChatGPT Plus lub Pro, GPT-5.2 jest właśnie wdrażany. Ceny API to 1,75 USD za milion tokenów wejściowych i 14 USD za milion tokenów wyjściowych, z 90% rabatem na tokeny z pamięci podręcznej.
Przeciętny użytkownik ChatGPT Enterprise już teraz zgłasza oszczędność 40-60 minut dziennie. Intensywni użytkownicy twierdzą, że oszczędzają ponad 10 godzin tygodniowo. Z GPT-5.2 te liczby będą tylko rosnąć.
Podsumowanie
GPT-5.2 nie jest po prostu lepszy. Przekracza progi, które uważaliśmy za oddalone o lata. Perfekcyjne wyniki w konkursach matematycznych. Pokonywanie profesjonalistów w ich własnej pracy. Niemal perfekcyjne rozumienie długiego kontekstu.
Obserwujemy w czasie rzeczywistym, jak zamyka się luka między asystą AI a możliwościami AI.
