

OpenAI veröffentlicht GPT-5.2: Die erste KI, die Branchenexperten übertrifft
OpenAI hat gerade GPT-5.2 veröffentlicht und die Benchmarks sind absolut beeindruckend. Das ist nicht einfach nur ein weiteres inkrementelles Update. Zum ersten Mal überhaupt schlägt ein KI-Modell konsequent menschliche Branchenexperten bei realer Wissensarbeit.
Die Benchmarks sprechen für sich
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Wissensarbeit) | 70,9% | 38,8% |
| SWE-Bench Pro (Software-Engineering) | 55,6% | 50,8% |
| SWE-Bench Verified (Software-Engineering) | 80,0% | 76,3% |
| GPQA Diamond (Wissenschaftliche Fragen) | 92,4% | 88,1% |
| CharXiv Reasoning (Wissenschaftliche Abbildungen) | 88,7% | 80,3% |
| AIME 2025 (Wettbewerbs-Mathematik) | 100,0% | 94,0% |
| FrontierMath Tier 1-3 (Fortgeschrittene Mathematik) | 40,3% | 31,0% |
| FrontierMath Tier 4 (Fortgeschrittene Mathematik) | 14,6% | 12,5% |
| ARC-AGI-1 (Abstraktes Denken) | 86,2% | 72,8% |
| ARC-AGI-2 (Abstraktes Denken) | 52,9% | 17,6% |
Schaut euch diesen ARC-AGI-2-Sprung an. Von 17,6% auf 52,9%. Das ist eine dreifache Verbesserung der echten abstrakten Denkfähigkeit in einer Generation.
Die wichtigste Zahl
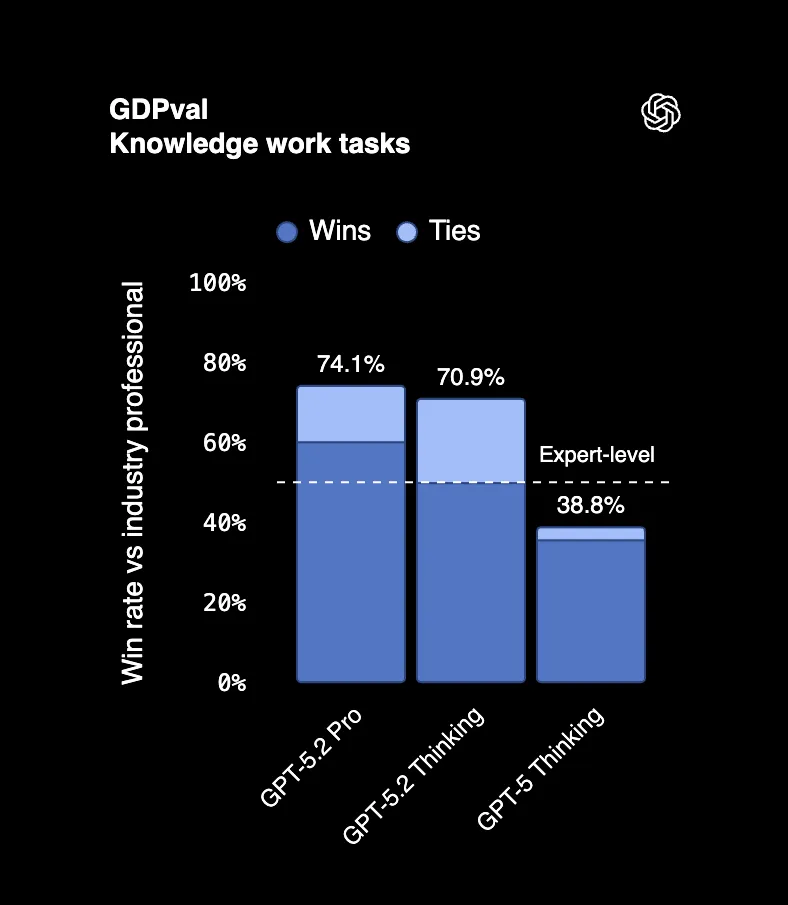
Bei GDPval, einem Benchmark zur Messung tatsächlicher professioneller Aufgaben in 44 Berufen, schlägt oder erreicht GPT-5.2 Thinking in 70,9% der Fälle Top-Branchenexperten. Wir sprechen hier von der Erstellung von Präsentationen, dem Aufbau von Tabellen, dem Verfassen von Berichten, den Dingen, für die Menschen sechsstellige Gehälter bekommen.
Ein Gutachter, der die Ergebnisse überprüfte, sagte, es "scheint von einem professionellen Unternehmen mit Personal erstellt worden zu sein". Das ist kein Tippfehler. Eine KI-Ausgabe wird mit der Arbeit eines ganzen Teams verwechselt.
Und hier kommt der Clou: GPT-5.2 hat diese Ergebnisse mit elfmal höherer Geschwindigkeit und weniger als 1% der Kosten von Fachexperten produziert.
100% bei Mathematik-Wettbewerben
GPT-5.2 Thinking erreichte 100% bei AIME 2025, einem renommierten Mathematik-Wettbewerb, der die meisten Menschen vor Rätsel stellt. Nicht 99%. Nicht 98%. Perfekte Punktzahl.
Bei FrontierMath, das Mathematik auf Expertenniveau testet, mit der selbst promovierte Mathematiker zu kämpfen haben, erreichte es 40,3%, gegenüber 31% bei GPT-5.1.
Programmieren wird ernst
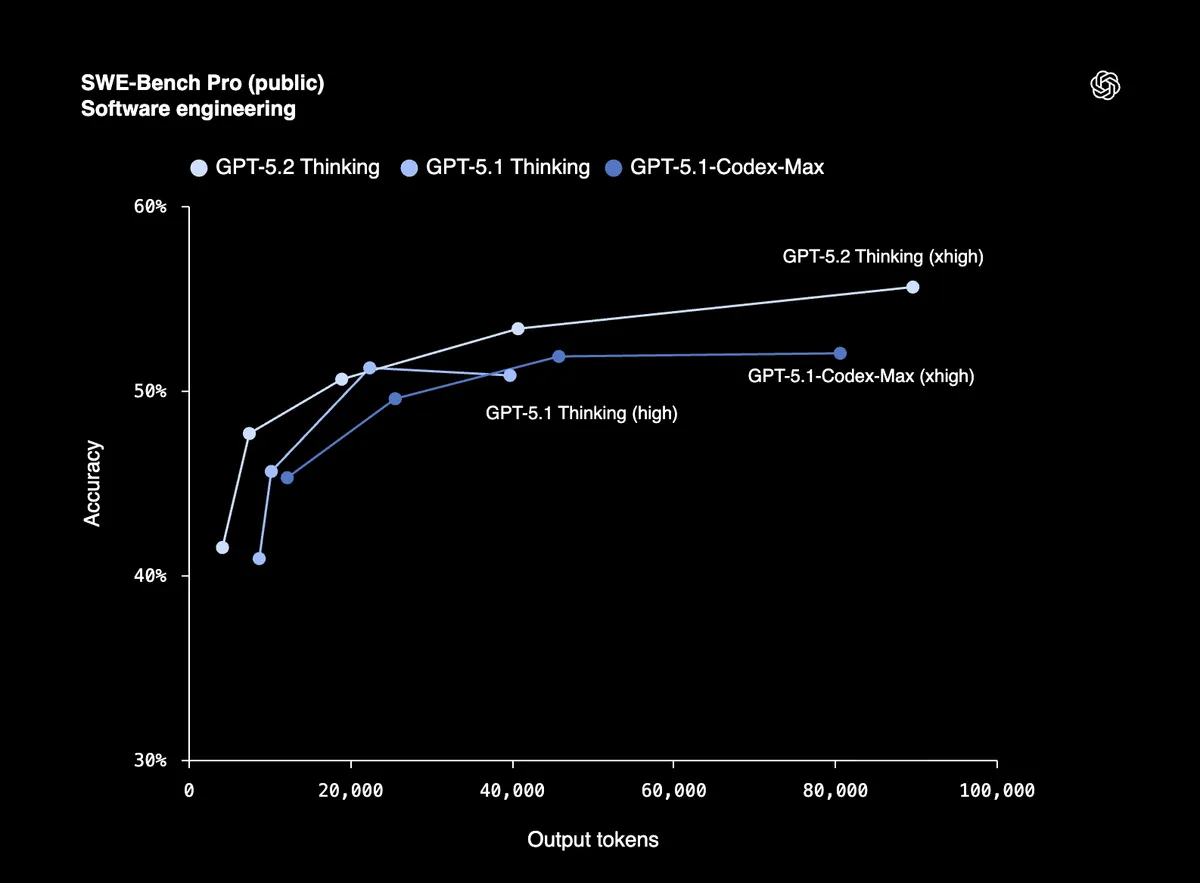
Eine Punktzahl von 80% bei SWE-Bench Verified bedeutet, dass GPT-5.2 zuverlässig Produktionscode debuggen, Features implementieren und große Codebasen mit minimaler Anleitung refaktorieren kann. SWE-Bench Pro testet reales Software-Engineering in vier Programmiersprachen, nicht nur Python.
Frühe Tester von Windsurf, JetBrains und Warp nennen es "den größten Sprung für GPT-Modelle beim agentischen Programmieren seit GPT-5."
30% weniger Halluzinationen
Das ist wichtig für alle, die KI professionell nutzen. GPT-5.2 Thinking produziert 30% weniger fehlerhafte Antworten im Vergleich zu GPT-5.1. Für Recherche, Analyse und Entscheidungsfindung ist das eine massive Verbesserung der Zuverlässigkeit.
Der Durchbruch bei langen Kontexten
GPT-5.2 ist das erste Modell, das bei Aufgaben mit langem Kontext bis zu 256.000 Token eine Genauigkeit von nahezu 100% erreicht. Das bedeutet, ihr könnt ihm ganze Codebasen, Verträge, Forschungsarbeiten oder Transkripte geben, und es behält tatsächlich die Kohärenz über alles hinweg bei.
Frühere Modelle verloren auf halbem Weg den Faden. GPT-5.2 nicht.
Vision, die tatsächlich funktioniert
Fehlerraten bei Diagramm-Reasoning und dem Verständnis von Software-Oberflächen wurden etwa halbiert. Das Modell kann jetzt Dashboards, technische Diagramme und Screenshots präzise interpretieren, was es für visuelle Analyseaufgaben wirklich nützlich macht.

Was das für euch bedeutet
Wenn ihr bereits für ChatGPT Plus oder Pro bezahlt, wird GPT-5.2 jetzt ausgerollt. Die API-Preise liegen bei 1,75 $ pro Million Input-Token und 14 $ pro Million Output-Token, mit 90% Rabatt auf gecachte Inputs.
Der durchschnittliche ChatGPT Enterprise-Nutzer berichtet bereits von einer Zeitersparnis von 40 bis 60 Minuten täglich. Intensivnutzer behaupten über 10 Stunden pro Woche. Mit GPT-5.2 werden diese Zahlen nur noch steigen.
Fazit
GPT-5.2 ist nicht einfach nur besser. Es überschreitet Schwellen, von denen wir dachten, sie lägen noch Jahre entfernt. Perfekte Punktzahlen bei Mathematik-Wettbewerben. Profis bei ihrer eigenen Arbeit schlagen. Nahezu perfektes Verständnis langer Kontexte.
Wir beobachten in Echtzeit, wie sich die Lücke zwischen KI-Unterstützung und KI-Fähigkeit schließt.
