

OpenAI, GPT-5.2 출시: 업계 전문가를 능가하는 최초의 AI
OpenAI가 방금 GPT-5.2를 공개했고, 벤치마크 결과는 정말 놀랍습니다. 이것은 단순한 점진적 업데이트가 아닙니다. 역사상 처음으로 AI 모델이 실제 지식 업무에서 업계 전문가들을 지속적으로 능가하고 있습니다.
벤치마크가 모든 것을 말해줍니다
| 벤치마크 | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
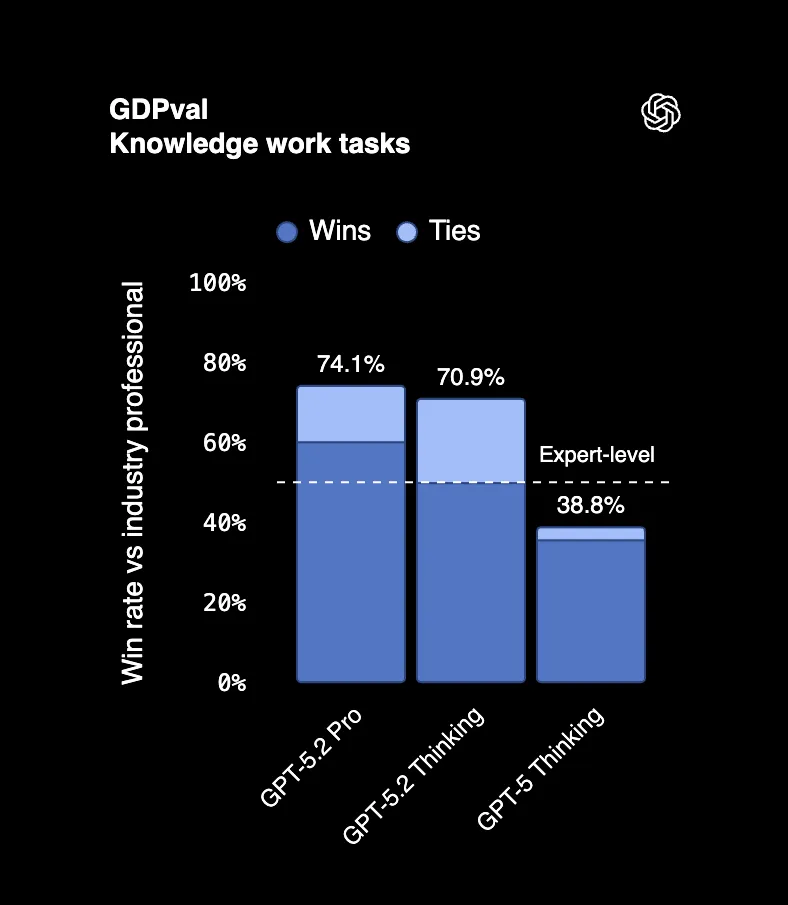
| GDPval (지식 업무) | 70.9% | 38.8% |
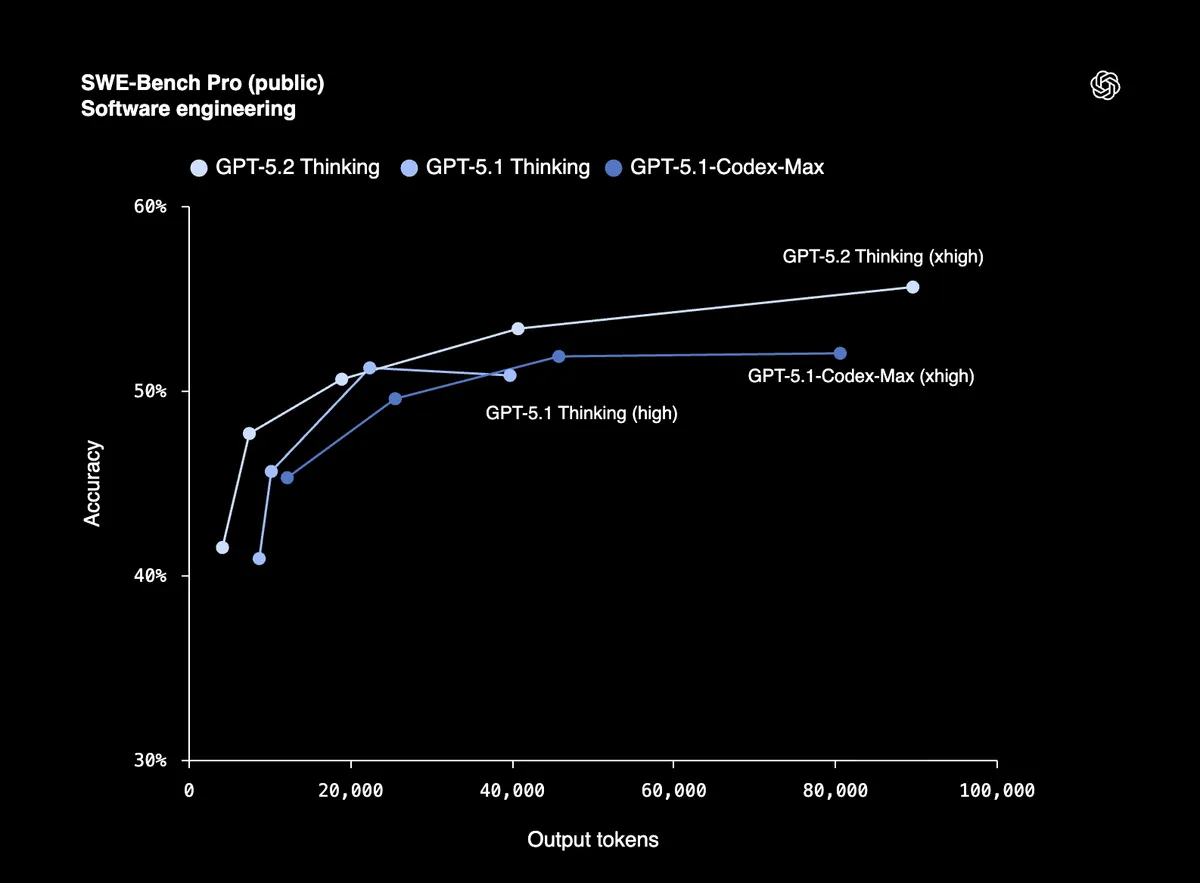
| SWE-Bench Pro (소프트웨어 엔지니어링) | 55.6% | 50.8% |
| SWE-Bench Verified (소프트웨어 엔지니어링) | 80.0% | 76.3% |
| GPQA Diamond (과학 질문) | 92.4% | 88.1% |
| CharXiv Reasoning (과학 도표) | 88.7% | 80.3% |
| AIME 2025 (경시 수학) | 100.0% | 94.0% |
| FrontierMath Tier 1-3 (고급 수학) | 40.3% | 31.0% |
| FrontierMath Tier 4 (고급 수학) | 14.6% | 12.5% |
| ARC-AGI-1 (추상적 추론) | 86.2% | 72.8% |
| ARC-AGI-2 (추상적 추론) | 52.9% | 17.6% |
ARC-AGI-2의 도약을 보세요. 17.6%에서 52.9%로 상승했습니다. 한 세대 만에 진정한 추상적 추론 능력이 3배 향상된 것입니다.
가장 중요한 수치
44개 직업에 걸친 실제 전문 업무를 측정하는 벤치마크인 GDPval에서 GPT-5.2 Thinking은 70.9%의 경우 최고 업계 전문가와 동등하거나 그들을 능가합니다. 프레젠테이션 작성, 스프레드시트 구축, 보고서 작성 등 사람들이 연봉 수억을 받으며 하는 일들을 말하는 것입니다.
결과물을 검토한 한 심사위원은 "전문 회사의 직원들이 작업한 것처럼 보인다"고 말했습니다. 오타가 아닙니다. AI 결과물이 전체 팀의 작업으로 오인될 정도입니다.
그리고 핵심은 이것입니다: GPT-5.2는 이러한 결과물을 전문가보다 11배 빠른 속도로, 비용은 1% 미만으로 생성했습니다.
경시 수학에서 100% 달성
GPT-5.2 Thinking은 대부분의 사람들을 당황하게 만드는 권위 있는 수학 경시대회인 AIME 2025에서 100%를 기록했습니다. 99%도, 98%도 아닙니다. 만점입니다.
박사급 수학자들도 어려워하는 전문가 수준의 수학을 테스트하는 FrontierMath에서는 GPT-5.1의 31%에서 40.3%로 향상되었습니다.
코딩이 본격화되었습니다
SWE-Bench Verified에서 80%를 기록했다는 것은 GPT-5.2가 최소한의 개입으로 프로덕션 코드를 안정적으로 디버깅하고, 기능을 구현하며, 대규모 코드베이스를 리팩토링할 수 있다는 의미입니다. SWE-Bench Pro는 Python뿐만 아니라 네 가지 프로그래밍 언어에 걸친 실제 소프트웨어 엔지니어링을 테스트합니다.
Windsurf, JetBrains, Warp의 초기 테스터들은 이를 "GPT-5 이후 에이전트 코딩에서 GPT 모델의 가장 큰 도약"이라고 부르고 있습니다.
환각 30% 감소
이것은 AI를 전문적으로 사용하는 모든 사람에게 중요합니다. GPT-5.2 Thinking은 GPT-5.1에 비해 오류가 있는 응답을 30% 적게 생성합니다. 연구, 분석, 의사결정에 있어 이는 엄청난 신뢰성 향상입니다.
긴 컨텍스트의 돌파구
GPT-5.2는 256k 토큰까지의 긴 컨텍스트 작업에서 거의 100%의 정확도를 달성한 최초의 모델입니다. 즉, 전체 코드베이스, 계약서, 연구 논문 또는 대화록을 입력해도 실제로 전체에 걸쳐 일관성을 유지한다는 의미입니다.
이전 모델들은 중간에 맥락을 잃곤 했습니다. GPT-5.2는 그렇지 않습니다.
실제로 작동하는 비전
차트 추론 및 소프트웨어 인터페이스 이해에 대한 오류율이 약 절반으로 감소했습니다. 이제 모델은 대시보드, 기술 다이어그램, 스크린샷을 정확하게 해석할 수 있어 시각적 분석 작업에 진정으로 유용합니다.

이것이 당신에게 의미하는 것
이미 ChatGPT Plus 또는 Pro를 구독하고 있다면 GPT-5.2가 지금 배포되고 있습니다. API 가격은 입력 토큰 백만 개당 $1.75, 출력 토큰 백만 개당 $14이며, 캐시된 입력에 대해서는 90% 할인이 적용됩니다.
평균적인 ChatGPT Enterprise 사용자는 이미 매일 40~60분을 절약한다고 보고합니다. 헤비 유저들은 주당 10시간 이상을 절약한다고 주장합니다. GPT-5.2로 인해 이 수치는 계속 증가할 것입니다.
결론
GPT-5.2는 단순히 더 나은 것이 아닙니다. 우리가 수년 후에나 가능할 것으로 생각했던 임계점을 넘고 있습니다. 수학 경시대회에서 만점, 전문가들을 그들의 업무에서 능가, 거의 완벽한 긴 컨텍스트 이해.
우리는 AI 보조와 AI 능력 사이의 격차가 실시간으로 좁혀지는 것을 목격하고 있습니다.
