

OpenAI GPT-5.2'yi Yayınladı: Sektör Profesyonellerini Geride Bırakan İlk Yapay Zeka
OpenAI yeni GPT-5.2'yi yayınladı ve kıyaslama sonuçları kelimenin tam anlamıyla çılgınca. Bu sadece bir artımlı güncelleme değil. İlk kez bir yapay zeka modeli, gerçek dünya bilgi işlerinde sektör profesyonellerini tutarlı bir şekilde geride bırakıyor.
Kıyaslamalar Kendi Kendine Konuşuyor
| Kıyaslama | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Bilgi işi) | %70.9 | %38.8 |
| SWE-Bench Pro (Yazılım mühendisliği) | %55.6 | %50.8 |
| SWE-Bench Verified (Yazılım mühendisliği) | %80.0 | %76.3 |
| GPQA Diamond (Bilim soruları) | %92.4 | %88.1 |
| CharXiv Reasoning (Bilimsel şekiller) | %88.7 | %80.3 |
| AIME 2025 (Yarışma matematiği) | %100.0 | %94.0 |
| FrontierMath Tier 1-3 (İleri matematik) | %40.3 | %31.0 |
| FrontierMath Tier 4 (İleri matematik) | %14.6 | %12.5 |
| ARC-AGI-1 (Soyut muhakeme) | %86.2 | %72.8 |
| ARC-AGI-2 (Soyut muhakeme) | %52.9 | %17.6 |
Şu ARC-AGI-2 sıçramasına bakın. %17.6'dan %52.9'a. Bu, gerçek soyut muhakeme yeteneğinde tek nesilde 3 kat iyileşme demek.
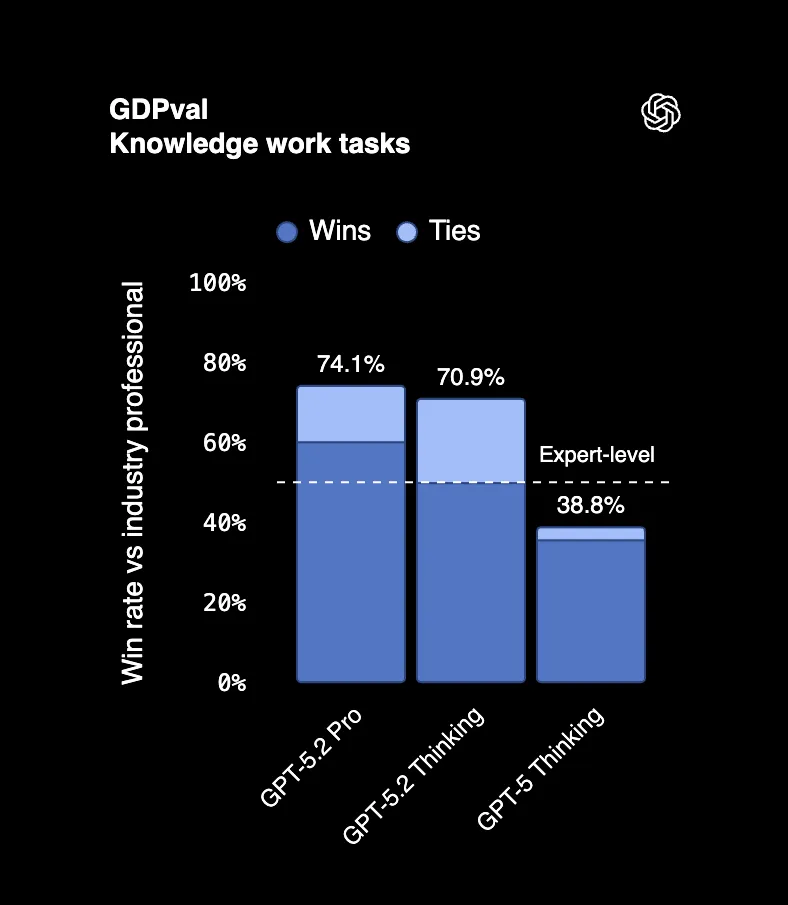
En Önemli Sayı
44 meslek genelinde gerçek profesyonel görevleri ölçen bir kıyaslama olan GDPval'de, GPT-5.2 Thinking zamanın %70.9'unda en iyi sektör profesyonellerini geride bırakıyor veya onlarla eşitleniyor. Sunum hazırlamak, elektronik tablolar oluşturmak, rapor yazmak gibi insanların altı haneli maaşlar aldığı işlerden bahsediyoruz.
Çıktıları inceleyen bir hakem, bunun "personeli olan profesyonel bir şirket tarafından yapılmış gibi göründüğünü" söyledi. Bu bir yazım hatası değil. Bir yapay zeka çıktısı, tüm bir ekibin işiyle karıştırılıyor.
Ve işin püf noktası şu: GPT-5.2 bu çıktıları uzman profesyonellere göre 11 kat daha hızlı ve maliyetin %1'inden daha azıyla üretti.
Yarışma Matematiğinde %100
GPT-5.2 Thinking, çoğu insanı zorlayan prestijli bir matematik yarışması olan AIME 2025'te %100 puan aldı. %99 değil. %98 değil. Tam puan.
Doktora dereceli matematikçilerin bile zorlandığı uzman düzeyinde matematiği test eden FrontierMath'te, GPT-5.1'deki %31'den %40.3'e yükseldi.
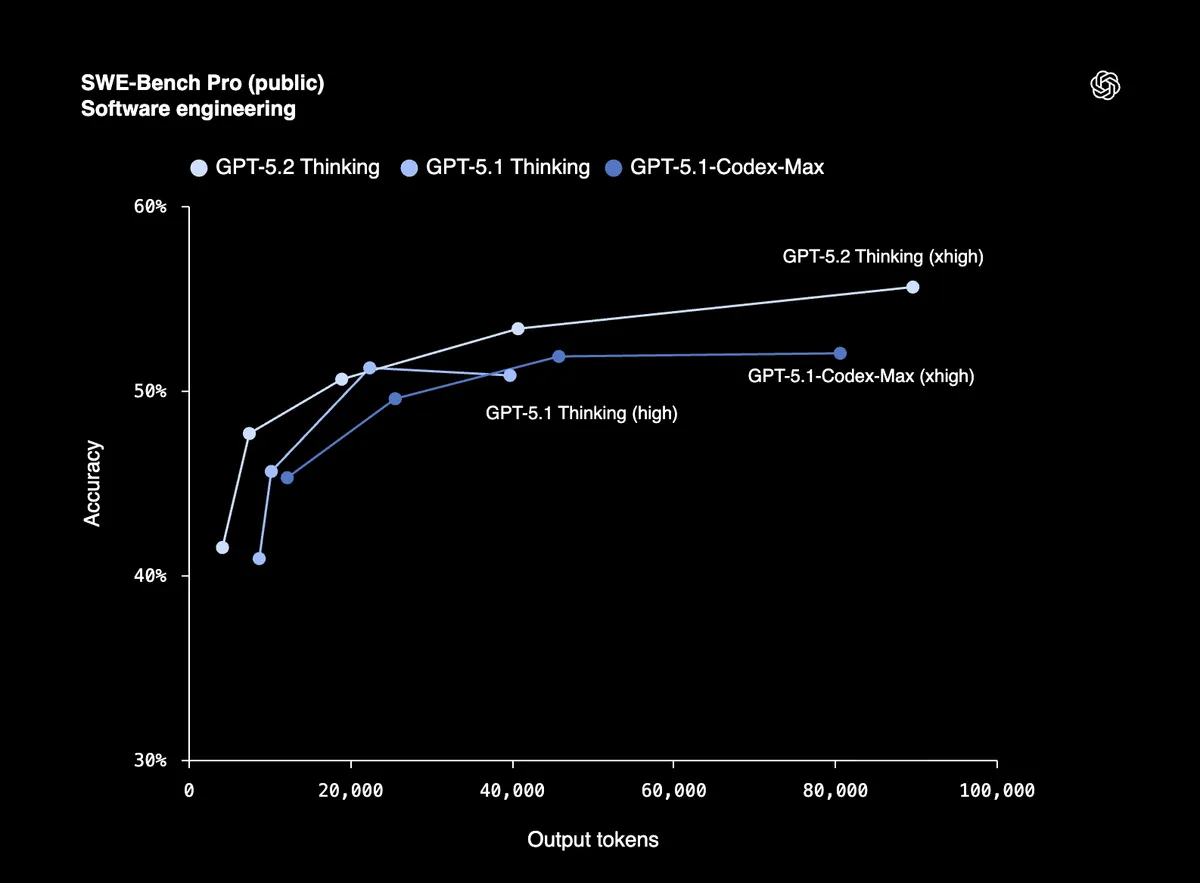
Kodlama Ciddi Bir Hal Aldı
SWE-Bench Verified'da %80 puan, GPT-5.2'nin üretim kodunda hata ayıklayabildiği, özellikler uygulayabildiği ve büyük kod tabanlarını minimum müdahaleyle yeniden yapılandırabildiği anlamına geliyor. SWE-Bench Pro, sadece Python değil, dört programlama dilinde gerçek dünya yazılım mühendisliğini test ediyor.
Windsurf, JetBrains ve Warp'tan erken test kullanıcıları bunu "GPT-5'ten bu yana aracı kodlamada GPT modelleri için en büyük sıçrama" olarak nitelendiriyor.
%30 Daha Az Halüsinasyon
Bu, yapay zekayı profesyonel olarak kullanan herkes için önemli. GPT-5.2 Thinking, GPT-5.1'e kıyasla %30 daha az hatalı yanıt üretiyor. Araştırma, analiz ve karar verme için bu muazzam bir güvenilirlik artışı.
Uzun Bağlam Atılımı
GPT-5.2, 256 bin token'a kadar uzun bağlam görevlerinde neredeyse %100 doğruluk elde eden ilk model. Bu, ona tüm kod tabanlarını, sözleşmeleri, araştırma makalelerini veya transkriptleri besleyebileceğiniz ve gerçekten tüm bunlar boyunca tutarlılığı koruduğu anlamına geliyor.
Önceki modeller yarı yolda konuyu kaybederdi. GPT-5.2 kaybetmiyor.
Gerçekten İşe Yarayan Görsel Yetenek
Grafik muhakemesi ve yazılım arayüzü anlama konusundaki hata oranları kabaca yarıya indirildi. Model artık kontrol panellerini, teknik diyagramları ve ekran görüntülerini doğru bir şekilde yorumlayabiliyor, bu da onu görsel analiz görevleri için gerçekten kullanışlı hale getiriyor.

Bu Sizin İçin Ne Anlama Geliyor
Zaten ChatGPT Plus veya Pro için ödeme yapıyorsanız, GPT-5.2 şu anda kullanıma sunuluyor. API fiyatlandırması, milyon giriş token'ı başına 1,75 dolar ve milyon çıkış token'ı başına 14 dolar, önbelleğe alınan girişlerde %90 indirim var.
Ortalama ChatGPT Enterprise kullanıcısı zaten günde 40-60 dakika tasarruf ettiğini bildiriyor. Yoğun kullanıcılar haftada 10 saatten fazla olduğunu iddia ediyor. GPT-5.2 ile bu rakamlar sadece artacak.
Sonuç
GPT-5.2 sadece daha iyi değil. Yıllar ötede olduğunu düşündüğümüz eşikleri aşıyor. Matematik yarışmalarında tam puan. Profesyonelleri kendi işlerinde geride bırakıyor. Neredeyse mükemmel uzun bağlam anlayışı.
Yapay zeka yardımı ile yapay zeka yeteneği arasındaki farkın gerçek zamanlı olarak kapandığına tanık oluyoruz.
