

OpenAI vydává GPT-5.2: První AI, která překonává profesionály z oboru
OpenAI právě představilo GPT-5.2 a výsledky benchmarků jsou naprosto šílené. Nejedná se jen o další postupnou aktualizaci. Poprvé v historii model AI konzistentně poráží profesionály z oboru v reálné znalostní práci.
Benchmarky mluví samy za sebe
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Znalostní práce) | 70,9 % | 38,8 % |
| SWE-Bench Pro (Softwarové inženýrství) | 55,6 % | 50,8 % |
| SWE-Bench Verified (Softwarové inženýrství) | 80,0 % | 76,3 % |
| GPQA Diamond (Vědecké otázky) | 92,4 % | 88,1 % |
| CharXiv Reasoning (Vědecké grafy) | 88,7 % | 80,3 % |
| AIME 2025 (Soutěžní matematika) | 100,0 % | 94,0 % |
| FrontierMath Tier 1-3 (Pokročilá matematika) | 40,3 % | 31,0 % |
| FrontierMath Tier 4 (Pokročilá matematika) | 14,6 % | 12,5 % |
| ARC-AGI-1 (Abstraktní uvažování) | 86,2 % | 72,8 % |
| ARC-AGI-2 (Abstraktní uvažování) | 52,9 % | 17,6 % |
Podívejte se na ten skok u ARC-AGI-2. Z 17,6 % na 52,9 %. To je trojnásobné zlepšení v opravdové schopnosti abstraktního uvažování za jednu generaci.
Číslo, na kterém záleží nejvíc
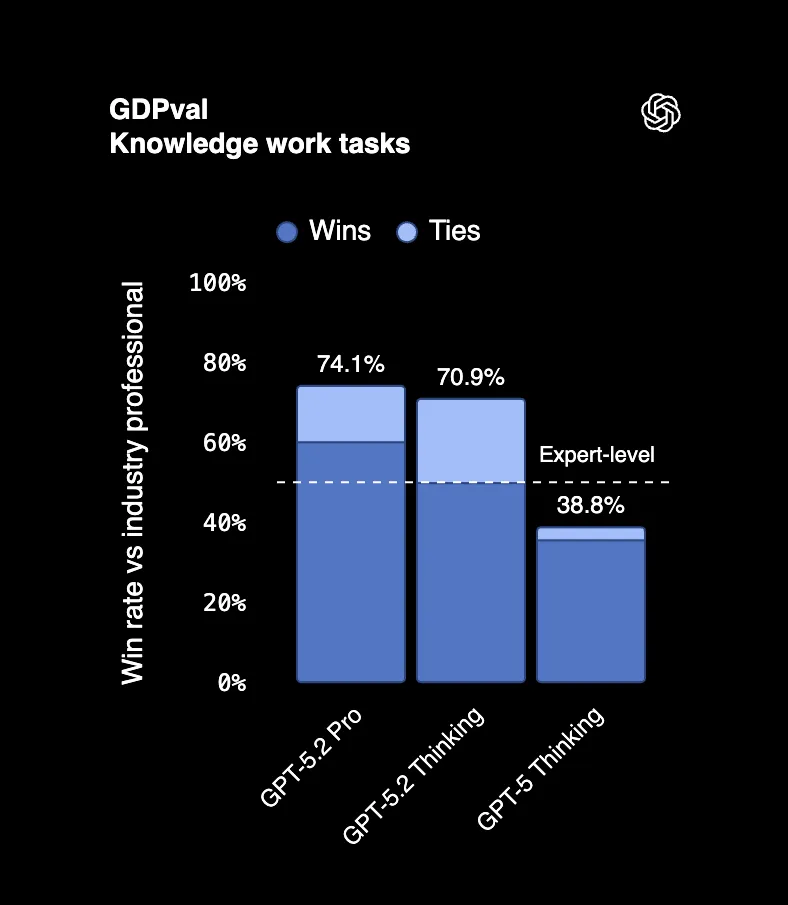
V benchmarku GDPval, který měří skutečné profesionální úkoly napříč 44 profesemi, GPT-5.2 Thinking poráží nebo vyrovnává špičkové profesionály z oboru v 70,9 % případů. Mluvíme o vytváření prezentací, tabulek, psaní zpráv, věcí, za které lidé dostávají šestimístné platy.
Jeden z hodnotitelů výstupů řekl, že to "vypadá, jako by to udělala profesionální firma s celým týmem zaměstnanců." To není překlep. Výstup AI je zaměňován za práci celého týmu.
A tady je ta hlavní pointa: GPT-5.2 vytvořilo tyto výstupy 11krát rychleji a za méně než 1 % nákladů ve srovnání s odbornými profesionály.
100% v soutěžní matematice
GPT-5.2 Thinking dosáhlo 100% úspěšnosti v AIME 2025, prestižní matematické soutěži, která mate většinu lidí. Ne 99 %. Ne 98 %. Perfektní skóre.
V FrontierMath, který testuje expertní matematiku, se kterou mají potíže i matematici s doktorátem, dosáhlo 40,3 %, což je nárůst z 31 % u GPT-5.1.
Programování se právě stalo vážnou záležitostí
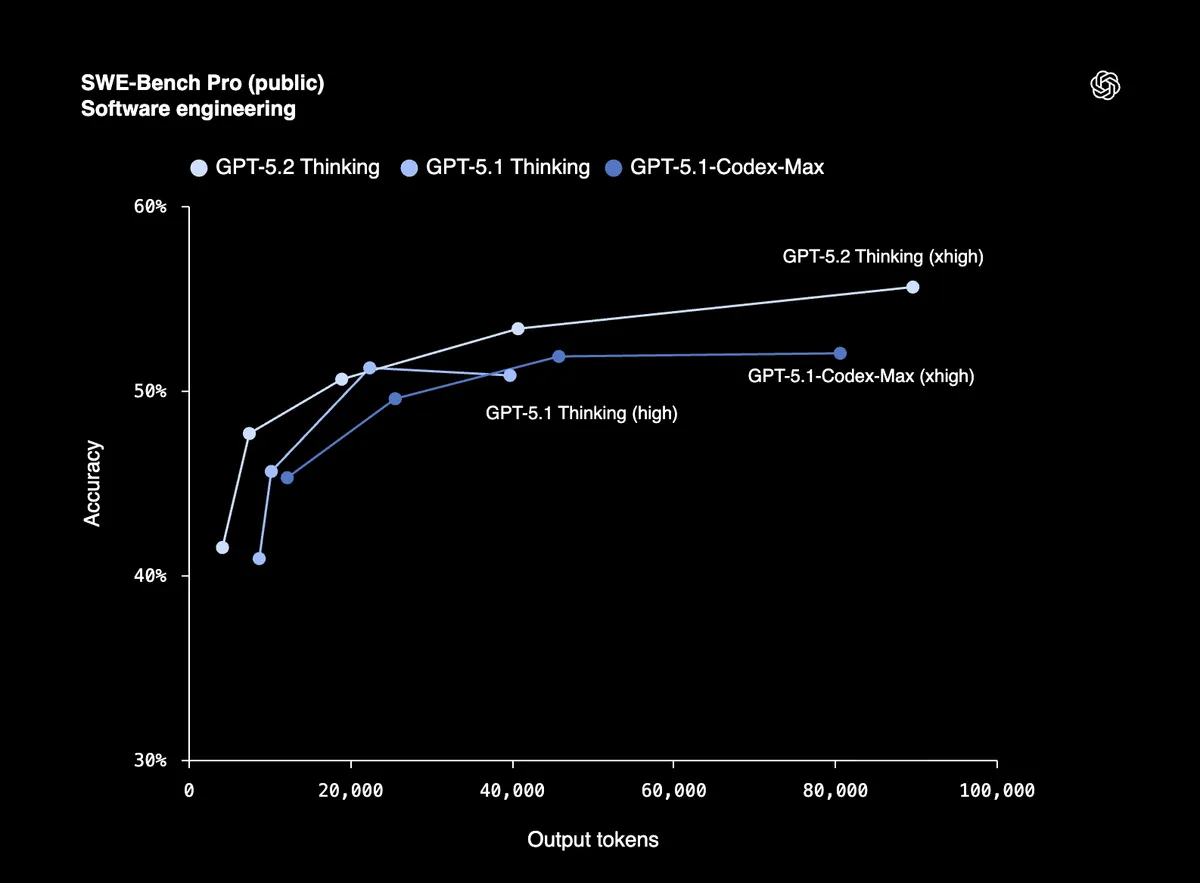
80% úspěšnost v SWE-Bench Verified znamená, že GPT-5.2 dokáže spolehlivě debugovat produkční kód, implementovat funkce a refaktorovat velké kódové báze s minimálním vedením. SWE-Bench Pro testuje reálné softwarové inženýrství napříč čtyřmi programovacími jazyky, nejen Pythonem.
První testeři z Windsurf, JetBrains a Warp to označují za "největší skok pro GPT modely v agentním programování od GPT-5."
O 30 % méně halucinací
Toto je důležité pro každého, kdo používá AI profesionálně. GPT-5.2 Thinking produkuje o 30 % méně odpovědí s chybami ve srovnání s GPT-5.1. Pro výzkum, analýzu a rozhodování je to obrovské zvýšení spolehlivosti.
Průlom v dlouhém kontextu
GPT-5.2 je první model, který dosahuje téměř 100% přesnosti v úlohách s dlouhým kontextem až do 256 tisíc tokenů. To znamená, že mu můžete nahrát celé kódové báze, smlouvy, výzkumné práce nebo přepisy a skutečně si udrží koherenci v celém rozsahu.
Předchozí modely by ztratily nить v polovině. GPT-5.2 ne.
Vidění, které skutečně funguje
Chybovost v uvažování nad grafy a porozumění softwarovým rozhraním byla snížena zhruba na polovinu. Model nyní dokáže přesně interpretovat dashboardy, technické diagramy a screenshoty, což z něj dělá skutečně užitečný nástroj pro úlohy vizuální analýzy.

Co to pro vás znamená
Pokud už platíte za ChatGPT Plus nebo Pro, GPT-5.2 se právě zavádí. Cena API je 1,75 $ za milion vstupních tokenů a 14 $ za milion výstupních tokenů, s 90% slevou na cachované vstupy.
Průměrný uživatel ChatGPT Enterprise už hlásí úsporu 40-60 minut denně. Intenzivní uživatelé tvrdí, že přes 10 hodin týdně. S GPT-5.2 tato čísla jen porostou.
Závěr
GPT-5.2 není jen lepší. Překračuje prahy, o kterých jsme si mysleli, že jsou vzdálené roky. Perfektní skóre v matematických soutěžích. Porážení profesionálů v jejich vlastní práci. Téměř dokonalé porozumění dlouhému kontextu.
V reálném čase sledujeme, jak se propast mezi asistencí AI a schopnostmi AI uzavírá.
