

OpenAI lanceert GPT-5.2: De eerste AI die beter presteert dan professionals uit de industrie
OpenAI heeft zojuist GPT-5.2 uitgebracht en de benchmarks zijn absoluut indrukwekkend. Dit is niet zomaar een incrementele update. Voor het eerst ooit verslaat een AI-model consequent menselijke professionals uit de industrie bij praktisch kenniswerk.
De benchmarks spreken voor zich
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Kenniswerk) | 70,9% | 38,8% |
| SWE-Bench Pro (Software engineering) | 55,6% | 50,8% |
| SWE-Bench Verified (Software engineering) | 80,0% | 76,3% |
| GPQA Diamond (Wetenschapsvragen) | 92,4% | 88,1% |
| CharXiv Reasoning (Wetenschappelijke figuren) | 88,7% | 80,3% |
| AIME 2025 (Wedstrijdwiskunde) | 100,0% | 94,0% |
| FrontierMath Tier 1-3 (Geavanceerde wiskunde) | 40,3% | 31,0% |
| FrontierMath Tier 4 (Geavanceerde wiskunde) | 14,6% | 12,5% |
| ARC-AGI-1 (Abstract redeneren) | 86,2% | 72,8% |
| ARC-AGI-2 (Abstract redeneren) | 52,9% | 17,6% |
Kijk naar die ARC-AGI-2 sprong. Van 17,6% naar 52,9%. Dat is een 3x verbetering in echt abstract redeneervermogen in één generatie.
Het cijfer dat het meest telt
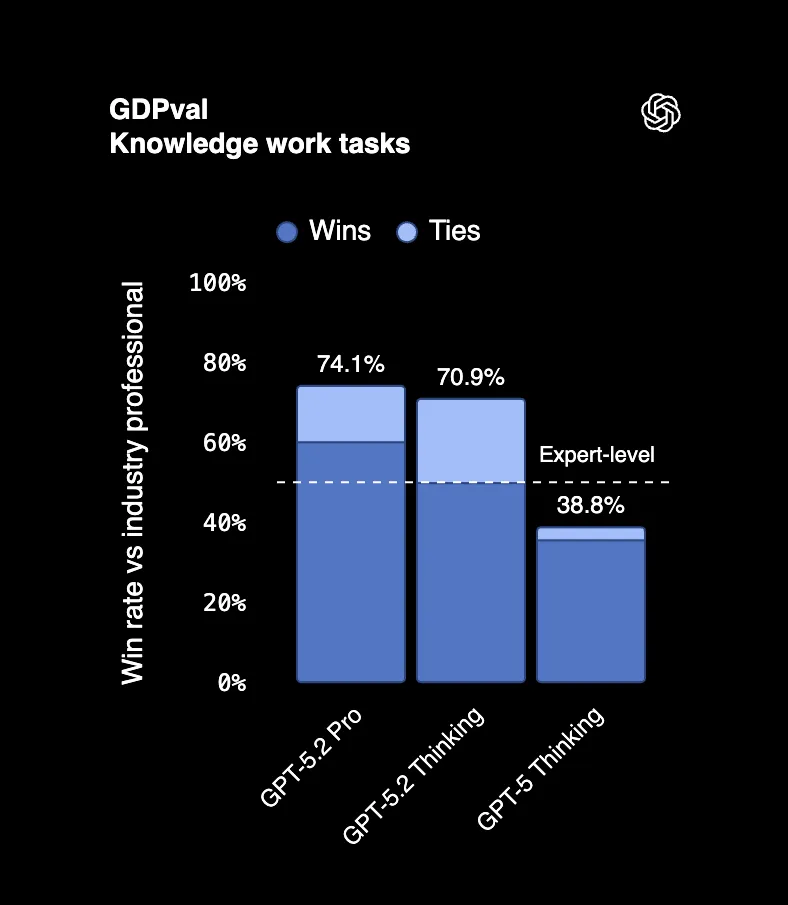
Op GDPval, een benchmark die daadwerkelijke professionele taken meet over 44 beroepen, verslaat of evenaart GPT-5.2 Thinking topprofessionals uit de industrie 70,9% van de tijd. We hebben het over het maken van presentaties, het bouwen van spreadsheets, het schrijven van rapporten, het soort werk waarvoor mensen zescijferige bedragen betaald krijgen.
Een beoordelaar die de resultaten bekeek, zei dat het "lijkt te zijn gedaan door een professioneel bedrijf met personeel." Dat is geen typfout. Een AI-resultaat wordt aangezien voor werk van een heel team.
En hier komt de clou: GPT-5.2 produceerde deze resultaten met 11x de snelheid en minder dan 1% van de kosten van professionele experts.
100% op wedstrijdwiskunde
GPT-5.2 Thinking scoorde 100% op AIME 2025, een prestigieuze wiskundewedstrijd waar de meeste mensen op vastlopen. Niet 99%. Niet 98%. Een perfecte score.
Op FrontierMath, dat expertniveau wiskunde test waar zelfs gepromoveerde wiskundigen moeite mee hebben, behaalde het 40,3%, een stijging van 31% met GPT-5.1.
Programmeren wordt serieus
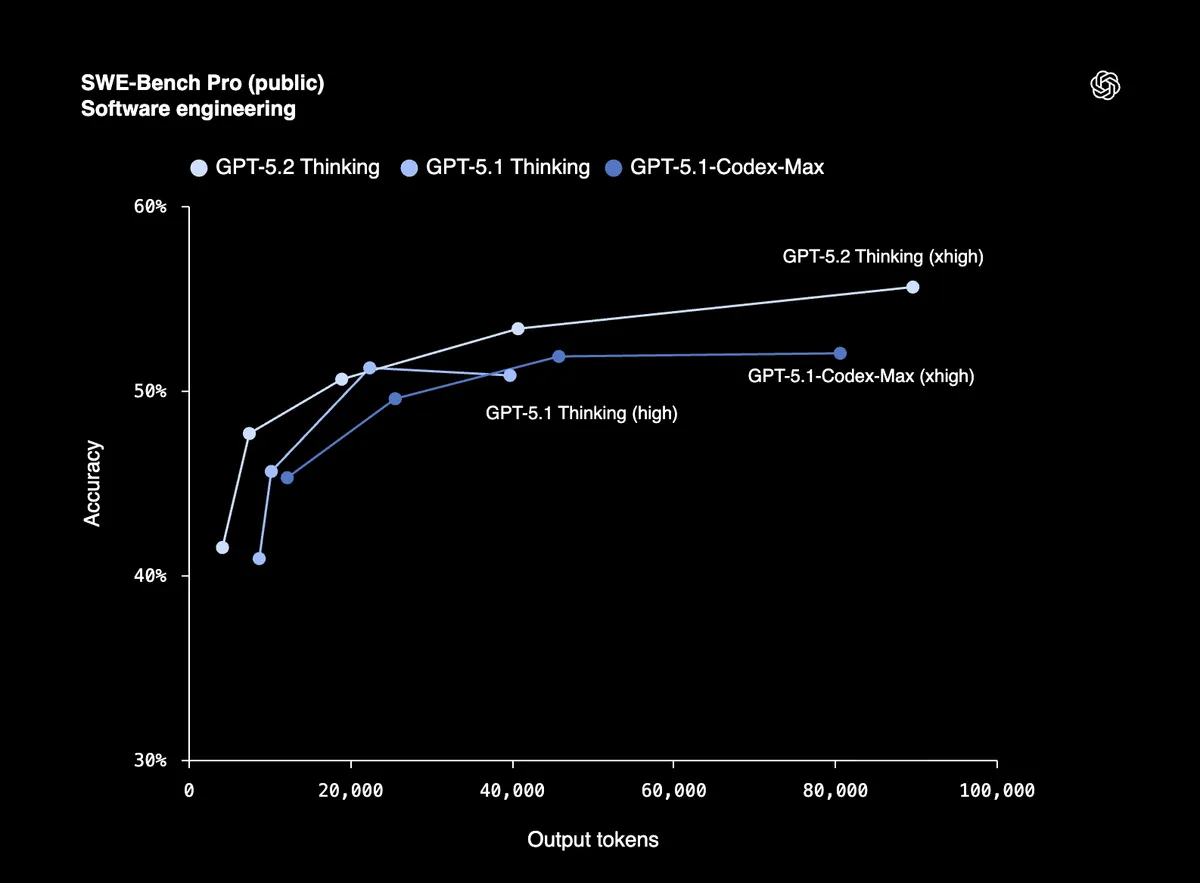
Een score van 80% op SWE-Bench Verified betekent dat GPT-5.2 betrouwbaar productiecode kan debuggen, functies kan implementeren en grote codebases kan refactoren met minimale begeleiding. SWE-Bench Pro test praktische software engineering in vier programmeertalen, niet alleen Python.
Vroege testers van Windsurf, JetBrains en Warp noemen het "de grootste sprong voor GPT-modellen in agentisch programmeren sinds GPT-5."
30% minder hallucinaties
Deze is belangrijk voor iedereen die AI professioneel gebruikt. GPT-5.2 Thinking produceert 30% minder reacties met fouten vergeleken met GPT-5.1. Voor onderzoek, analyse en besluitvorming is dat een enorme betrouwbaarheidsboost.
De doorbraak in lange context
GPT-5.2 is het eerste model dat bijna 100% nauwkeurigheid behaalt bij taken met lange context tot 256k tokens. Dat betekent dat je het hele codebases, contracten, onderzoekspapers of transcripties kunt voeren, en het daadwerkelijk coherentie behoudt over het geheel.
Eerdere modellen raakten halverwege de draad kwijt. GPT-5.2 niet.
Visie die echt werkt
Foutpercentages bij grafiekredenering en begrip van software-interfaces werden ongeveer gehalveerd. Het model kan nu nauwkeurig dashboards, technische diagrammen en screenshots interpreteren, waardoor het echt bruikbaar is voor visuele analysetaken.

Wat dit voor jou betekent
Als je al betaalt voor ChatGPT Plus of Pro, wordt GPT-5.2 nu uitgerold. API-prijzen zijn $1,75 per miljoen invoertokens en $14 per miljoen uitvoertokens, met 90% korting op gecachte invoer.
De gemiddelde ChatGPT Enterprise-gebruiker meldt al een tijdsbesparing van 40-60 minuten per dag. Intensieve gebruikers claimen meer dan 10 uur per week. Met GPT-5.2 zullen die cijfers alleen maar stijgen.
De conclusie
GPT-5.2 is niet alleen beter. Het overschrijdt drempels waarvan we dachten dat ze nog jaren weg waren. Perfecte scores op wiskundewedstrijden. Professionals verslaan in hun eigen vak. Bijna perfect begrip van lange context.
We zien de kloof tussen AI-assistentie en AI-capaciteit in realtime kleiner worden.
