

OpenAI 发布 GPT-5.2:首个超越行业专业人士的 AI
OpenAI 刚刚发布了 GPT-5.2,其基准测试结果令人震惊。这不仅仅是又一次渐进式更新。这是有史以来第一次,一个 AI 模型在实际知识工作中持续击败人类行业专业人士。
基准测试数据不言自明
| 基准测试 | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (知识工作) | 70.9% | 38.8% |
| SWE-Bench Pro (软件工程) | 55.6% | 50.8% |
| SWE-Bench Verified (软件工程) | 80.0% | 76.3% |
| GPQA Diamond (科学问题) | 92.4% | 88.1% |
| CharXiv Reasoning (科学图表) | 88.7% | 80.3% |
| AIME 2025 (竞赛数学) | 100.0% | 94.0% |
| FrontierMath Tier 1-3 (高级数学) | 40.3% | 31.0% |
| FrontierMath Tier 4 (高级数学) | 14.6% | 12.5% |
| ARC-AGI-1 (抽象推理) | 86.2% | 72.8% |
| ARC-AGI-2 (抽象推理) | 52.9% | 17.6% |
看看 ARC-AGI-2 的飞跃。从 17.6% 到 52.9%。这是真正抽象推理能力在一代之间实现的 3 倍提升。
最重要的数字
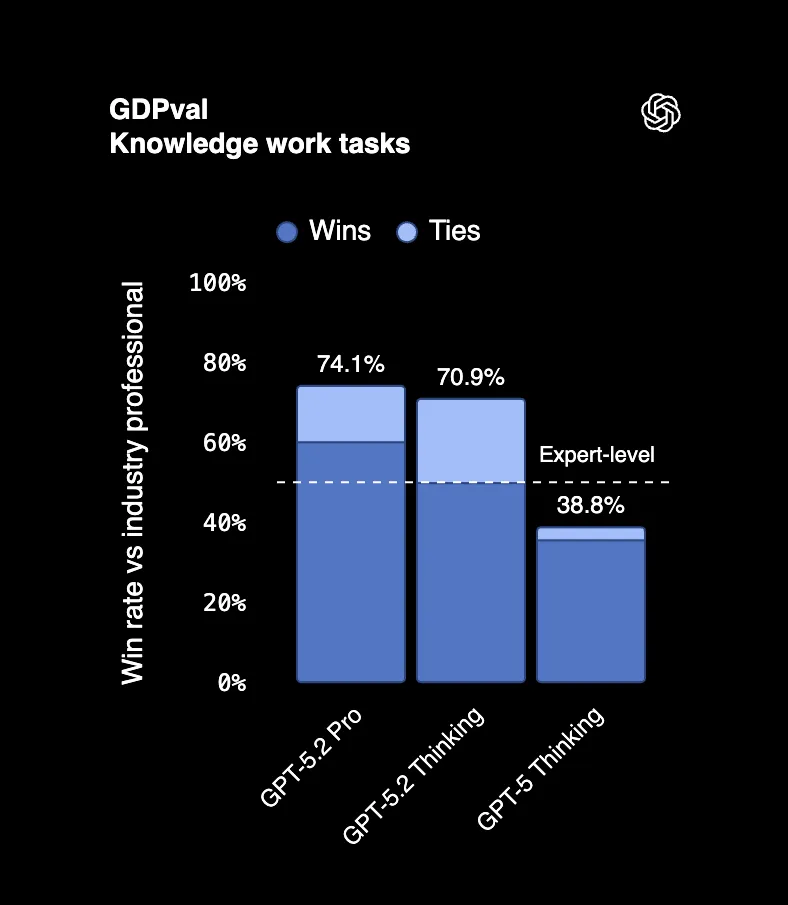
在 GDPval 这个衡量 44 个职业实际专业任务的基准测试中,GPT-5.2 Thinking 在 70.9% 的情况下击败或持平顶级行业专业人士。我们说的是制作演示文稿、构建电子表格、撰写报告,这些人们拿六位数薪水做的工作。
一位评审输出结果的评委表示,这些成果「看起来像是由一家拥有员工的专业公司完成的」。这不是打字错误。AI 的输出被误认为是整个团队的工作成果。
而且关键是:GPT-5.2 产出这些结果的速度是专家的 11 倍,成本不到专家的 1%。
竞赛数学 100% 满分
GPT-5.2 Thinking 在 AIME 2025 上获得 100% 的成绩,这是一项让大多数人类都感到困难的著名数学竞赛。不是 99%。不是 98%。满分。
在 FrontierMath 上,这个测试连博士数学家都感到吃力的专家级数学,它达到了 40.3%,高于 GPT-5.1 的 31%。
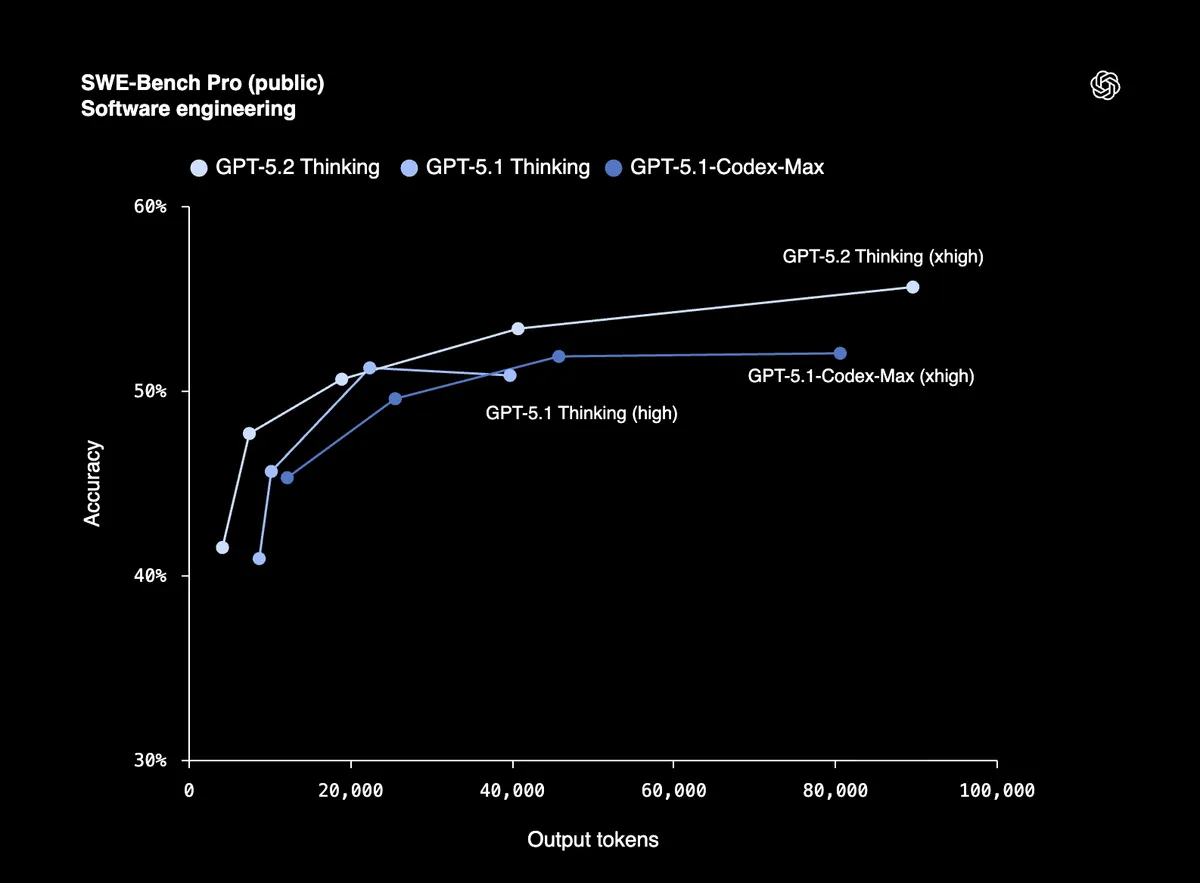
编程能力大幅提升
在 SWE-Bench Verified 上 80% 的得分意味着 GPT-5.2 可以可靠地调试生产代码、实现功能,并在最少人工干预的情况下重构大型代码库。SWE-Bench Pro 测试四种编程语言的实际软件工程能力,而不仅仅是 Python。
来自 Windsurf、JetBrains 和 Warp 的早期测试者称其为「自 GPT-5 以来 GPT 模型在智能编程方面的最大飞跃」。
幻觉减少 30%
这一点对于专业使用 AI 的任何人都很重要。与 GPT-5.1 相比,GPT-5.2 Thinking 产生错误响应的情况减少了 30%。对于研究、分析和决策制定来说,这是可靠性的巨大提升。
长上下文的突破
GPT-5.2 是第一个在长达 256k tokens 的长上下文任务中实现接近 100% 准确率的模型。这意味着你可以向它输入整个代码库、合同、研究论文或记录,它实际上能在所有内容中保持连贯性。
以前的模型会在中途失去重点。GPT-5.2 不会。
真正有效的视觉能力
图表推理和软件界面理解的错误率大约减半。该模型现在可以准确解读仪表板、技术图表和屏幕截图,使其在视觉分析任务中真正有用。

这对你意味着什么
如果你已经订阅了 ChatGPT Plus 或 Pro,GPT-5.2 正在推出。API 定价为每百万输入 tokens 1.75 美元,每百万输出 tokens 14 美元,缓存输入可享受 90% 折扣。
普通 ChatGPT Enterprise 用户已经报告每天节省 40-60 分钟。重度用户声称每周节省超过 10 小时。有了 GPT-5.2,这些数字只会继续上升。
结论
GPT-5.2 不仅仅是更好。它正在跨越我们认为还需要数年才能达到的门槛。数学竞赛满分。在专业人士自己的工作中击败他们。接近完美的长上下文理解。
我们正在实时见证 AI 辅助与 AI 能力之间的差距正在缩小。
