

OpenAI تطلق GPT-5.2: أول ذكاء اصطناعي يتفوق على المحترفين في الصناعة
أطلقت OpenAI للتو GPT-5.2 والمعايير القياسية مذهلة تماماً. هذا ليس مجرد تحديث تدريجي آخر. للمرة الأولى على الإطلاق، يتفوق نموذج ذكاء اصطناعي باستمرار على المحترفين البشريين في الصناعة في العمل المعرفي الواقعي.
المعايير القياسية تتحدث عن نفسها
| المعيار القياسي | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (العمل المعرفي) | 70.9% | 38.8% |
| SWE-Bench Pro (هندسة البرمجيات) | 55.6% | 50.8% |
| SWE-Bench Verified (هندسة البرمجيات) | 80.0% | 76.3% |
| GPQA Diamond (أسئلة علمية) | 92.4% | 88.1% |
| CharXiv Reasoning (الأشكال العلمية) | 88.7% | 80.3% |
| AIME 2025 (مسابقات الرياضيات) | 100.0% | 94.0% |
| FrontierMath Tier 1-3 (رياضيات متقدمة) | 40.3% | 31.0% |
| FrontierMath Tier 4 (رياضيات متقدمة) | 14.6% | 12.5% |
| ARC-AGI-1 (التفكير المجرد) | 86.2% | 72.8% |
| ARC-AGI-2 (التفكير المجرد) | 52.9% | 17.6% |
انظر إلى تلك القفزة في ARC-AGI-2. من 17.6% إلى 52.9%. هذا تحسن بمقدار 3 أضعاف في القدرة الحقيقية على التفكير المجرد في جيل واحد.
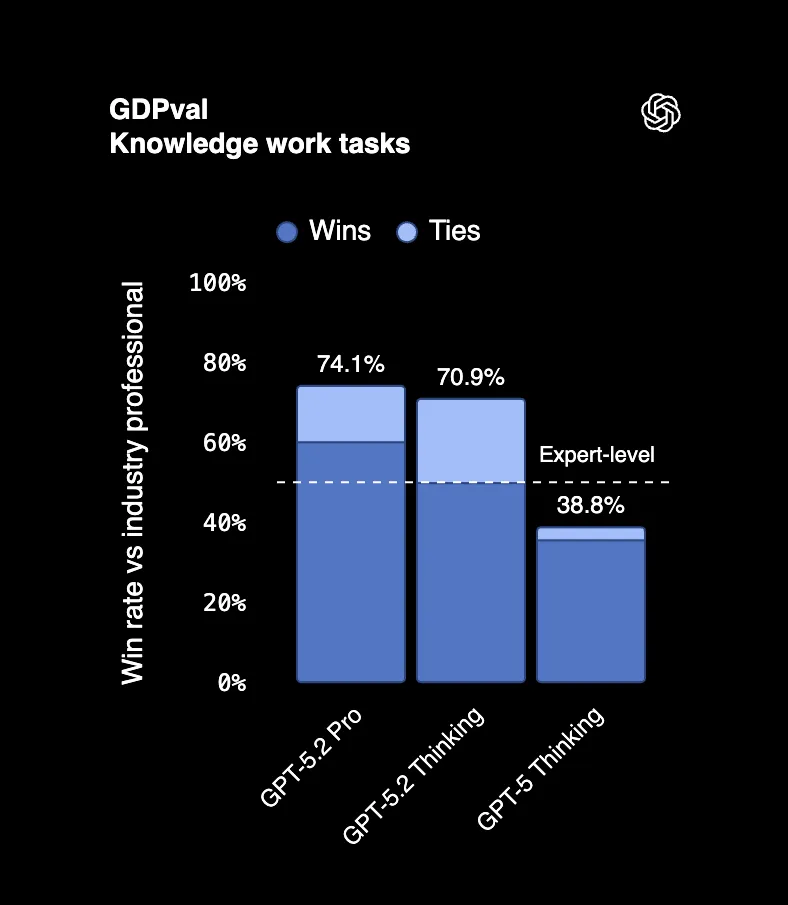
الرقم الأكثر أهمية
في معيار GDPval، وهو معيار يقيس المهام المهنية الفعلية عبر 44 مهنة، يتفوق GPT-5.2 Thinking أو يتعادل مع كبار المحترفين في الصناعة بنسبة 70.9% من الوقت. نحن نتحدث عن إنشاء العروض التقديمية، وبناء جداول البيانات، وكتابة التقارير، الأشياء التي يتقاضى الناس ستة أرقام مقابل القيام بها.
قال أحد الحكام الذين راجعوا المخرجات إنها "يبدو أنها تمت بواسطة شركة محترفة مع موظفين." هذا ليس خطأ مطبعي. مخرجات الذكاء الاصطناعي يتم الخلط بينها وبين عمل فريق كامل.
وهذه هي المفاجأة: أنتج GPT-5.2 هذه المخرجات بسرعة 11 ضعفاً وبأقل من 1% من تكلفة المحترفين الخبراء.
100% في مسابقات الرياضيات
سجل GPT-5.2 Thinking 100% في AIME 2025، وهي مسابقة رياضيات مرموقة تحير معظم البشر. ليس 99%. ليس 98%. درجة كاملة.
في FrontierMath، الذي يختبر الرياضيات على مستوى الخبراء والتي يعاني منها حتى علماء الرياضيات الحاصلون على درجة الدكتوراه، حقق 40.3%، ارتفاعاً من 31% مع GPT-5.1.
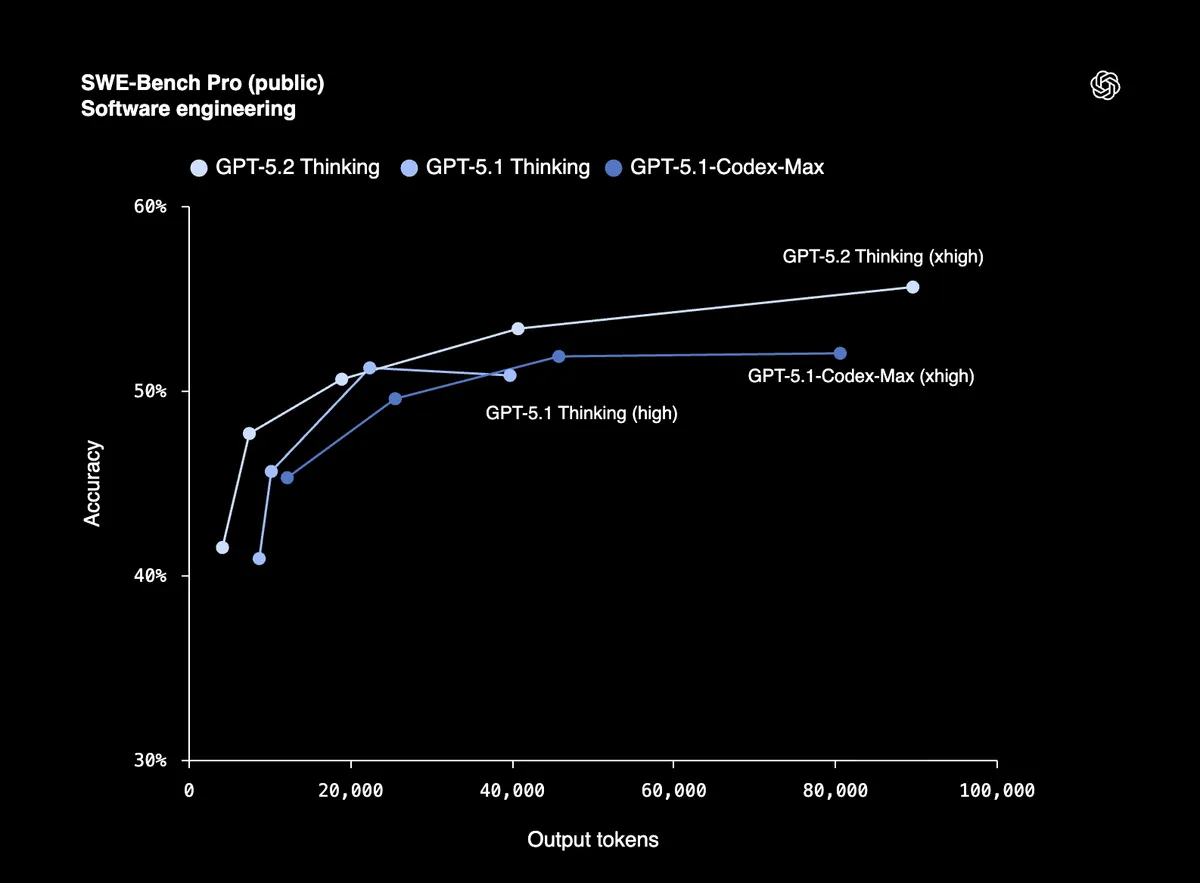
البرمجة أصبحت جادة الآن
درجة 80% في SWE-Bench Verified تعني أن GPT-5.2 يمكنه تصحيح أخطاء كود الإنتاج بشكل موثوق، وتنفيذ الميزات، وإعادة هيكلة قواعد الأكواد الكبيرة بأقل قدر من التوجيه. يختبر SWE-Bench Pro هندسة البرمجيات الواقعية عبر أربع لغات برمجة، وليس Python فقط.
المختبرون الأوائل من Windsurf وJetBrains وWarp يصفونه بأنه "أكبر قفزة لنماذج GPT في البرمجة الوكيلة منذ GPT-5."
30% أقل من الهلوسات
هذا مهم لأي شخص يستخدم الذكاء الاصطناعي بشكل احترافي. ينتج GPT-5.2 Thinking 30% أقل من الاستجابات التي تحتوي على أخطاء مقارنة بـ GPT-5.1. بالنسبة للبحث والتحليل واتخاذ القرارات، هذه زيادة هائلة في الموثوقية.
اختراق السياق الطويل
GPT-5.2 هو أول نموذج يحقق دقة قريبة من 100% في مهام السياق الطويل حتى 256 ألف رمز. هذا يعني أنه يمكنك تغذيته بقواعد أكواد كاملة، وعقود، وأوراق بحثية، أو نصوص، وهو يحافظ فعلياً على التماسك عبر كل ذلك.
كانت النماذج السابقة تفقد التركيز في منتصف الطريق. GPT-5.2 لا يفعل ذلك.
رؤية تعمل فعلياً
تم تقليص معدلات الخطأ في استنتاج الرسوم البيانية وفهم واجهة البرمجيات إلى النصف تقريباً. يمكن للنموذج الآن تفسير لوحات المعلومات والرسوم البيانية التقنية ولقطات الشاشة بدقة، مما يجعله مفيداً حقاً لمهام التحليل البصري.

ماذا يعني هذا بالنسبة لك
إذا كنت تدفع بالفعل مقابل ChatGPT Plus أو Pro، فإن GPT-5.2 يتم طرحه الآن. تسعير API هو 1.75 دولار لكل مليون رمز إدخال و14 دولاراً لكل مليون رمز إخراج، مع خصم 90% على المدخلات المخزنة مؤقتاً.
يُبلغ متوسط مستخدم ChatGPT Enterprise بالفعل عن توفير 40-60 دقيقة يومياً. يدعي المستخدمون الكثيفون أكثر من 10 ساعات في الأسبوع. مع GPT-5.2، هذه الأرقام ستزداد فقط.
الخلاصة
GPT-5.2 ليس أفضل فقط. إنه يعبر عتبات كنا نعتقد أنها على بعد سنوات. درجات كاملة في مسابقات الرياضيات. التفوق على المحترفين في وظائفهم الخاصة. فهم شبه مثالي للسياق الطويل.
نحن نشاهد الفجوة بين مساعدة الذكاء الاصطناعي وقدرة الذكاء الاصطناعي تغلق في الوقت الفعلي.
