

OpenAI lanza GPT-5.2: La primera IA que supera a profesionales de la industria
OpenAI acaba de lanzar GPT-5.2 y los resultados son absolutamente impresionantes. Esto no es solo otra actualización incremental. Por primera vez en la historia, un modelo de IA supera consistentemente a profesionales de la industria en trabajo de conocimiento del mundo real.
Los resultados hablan por sí mismos
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Trabajo de conocimiento) | 70.9% | 38.8% |
| SWE-Bench Pro (Ingeniería de software) | 55.6% | 50.8% |
| SWE-Bench Verified (Ingeniería de software) | 80.0% | 76.3% |
| GPQA Diamond (Preguntas de ciencia) | 92.4% | 88.1% |
| CharXiv Reasoning (Figuras científicas) | 88.7% | 80.3% |
| AIME 2025 (Matemáticas de competición) | 100.0% | 94.0% |
| FrontierMath Tier 1-3 (Matemáticas avanzadas) | 40.3% | 31.0% |
| FrontierMath Tier 4 (Matemáticas avanzadas) | 14.6% | 12.5% |
| ARC-AGI-1 (Razonamiento abstracto) | 86.2% | 72.8% |
| ARC-AGI-2 (Razonamiento abstracto) | 52.9% | 17.6% |
Mira ese salto en ARC-AGI-2. De 17.6% a 52.9%. Eso es una mejora de 3x en capacidad genuina de razonamiento abstracto en una sola generación.
El número que más importa
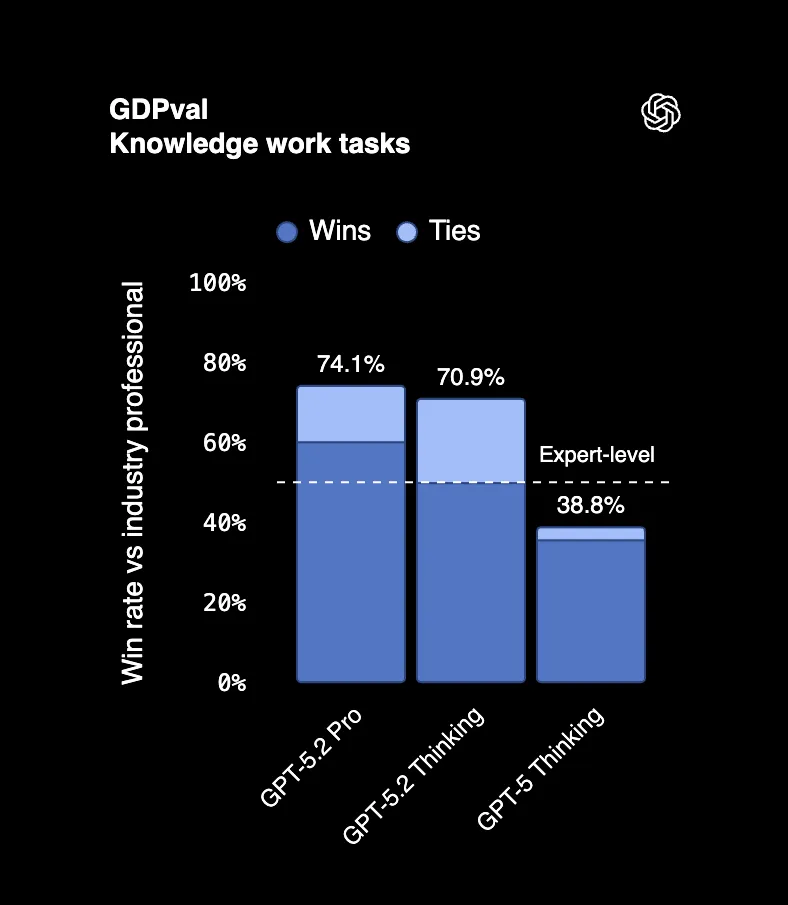
En GDPval, un benchmark que mide tareas profesionales reales en 44 ocupaciones, GPT-5.2 Thinking supera o iguala a los mejores profesionales de la industria el 70.9% de las veces. Estamos hablando de crear presentaciones, construir hojas de cálculo, redactar informes, las cosas por las que la gente cobra seis cifras.
Un juez que revisó los resultados dijo que "parece haber sido hecho por una empresa profesional con personal". Eso no es un error. Un resultado de IA confundido con el trabajo de un equipo completo.
Y aquí está lo mejor: GPT-5.2 produjo estos resultados a 11 veces la velocidad y menos del 1% del costo de profesionales expertos.
100% en matemáticas de competición
GPT-5.2 Thinking obtuvo 100% en AIME 2025, una prestigiosa competición de matemáticas que deja perplejos a la mayoría de humanos. No 99%. No 98%. Puntuación perfecta.
En FrontierMath, que evalúa matemáticas de nivel experto con las que incluso matemáticos con doctorado tienen dificultades, alcanzó el 40.3%, frente al 31% con GPT-5.1.
La programación se pone seria
Una puntuación del 80% en SWE-Bench Verified significa que GPT-5.2 puede depurar código de producción de manera confiable, implementar funcionalidades y refactorizar grandes bases de código con mínima supervisión. SWE-Bench Pro evalúa ingeniería de software del mundo real en cuatro lenguajes de programación, no solo Python.
Los primeros evaluadores de Windsurf, JetBrains y Warp lo llaman "el mayor salto para los modelos GPT en programación agéntica desde GPT-5".
30% menos alucinaciones
Esto importa para cualquiera que use IA profesionalmente. GPT-5.2 Thinking produce 30% menos respuestas con errores en comparación con GPT-5.1. Para investigación, análisis y toma de decisiones, eso es un aumento masivo en confiabilidad.
El avance en contexto largo
GPT-5.2 es el primer modelo en lograr casi 100% de precisión en tareas de contexto largo de hasta 256k tokens. Eso significa que puedes alimentarlo con bases de código completas, contratos, artículos de investigación o transcripciones, y realmente mantiene la coherencia en todo.
Los modelos anteriores perdían el hilo a mitad de camino. GPT-5.2 no lo hace.
Visión que realmente funciona
Las tasas de error en razonamiento de gráficos y comprensión de interfaces de software se redujeron aproximadamente a la mitad. El modelo ahora puede interpretar con precisión paneles de control, diagramas técnicos y capturas de pantalla, haciéndolo genuinamente útil para tareas de análisis visual.

Qué significa esto para ti
Si ya estás pagando por ChatGPT Plus o Pro, GPT-5.2 se está implementando ahora. El precio de la API es de $1.75 por millón de tokens de entrada y $14 por millón de tokens de salida, con un descuento del 90% en entradas en caché.
El usuario promedio de ChatGPT Enterprise ya reporta ahorrar entre 40 y 60 minutos diarios. Los usuarios intensivos afirman más de 10 horas por semana. Con GPT-5.2, esos números solo van a aumentar.
La conclusión
GPT-5.2 no es solo mejor. Está cruzando umbrales que pensábamos estaban a años de distancia. Puntuaciones perfectas en competiciones de matemáticas. Superando a profesionales en sus propios trabajos. Comprensión de contexto largo casi perfecta.
Estamos viendo cómo la brecha entre asistencia de IA y capacidad de IA se cierra en tiempo real.
