
Lors du CES 2026, NVIDIA a annoncé ce qui pourrait être la publication open-source d'IA la plus importante à ce jour. L'entreprise a dévoilé de nouveaux modèles, ensembles de données et outils couvrant tout, de la reconnaissance vocale à la découverte de médicaments.
L'ampleur est remarquable :
- 10 billions de tokens d'entraînement linguistique
- 500 000 trajectoires robotiques
- 455 000 structures protéiques
- 100 téraoctets de données de capteurs de véhicules
Des entreprises majeures, dont Bosch, Salesforce, Uber, Palantir et CrowdStrike, développent déjà des solutions basées sur ces technologies.
Nemotron RAG : Recherche documentaire plus intelligente

Modèle d'embedding : Llama-Nemotron-Embed-VL-1B-V2 (1,7 milliard de paramètres)
Modèle de reclassement : Llama-Nemotron-Rerank-VL-1B-V2 (1,7 milliard de paramètres)
Également disponible : Modèle d'embedding texte uniquement de 8 milliards de paramètres
Longueur de contexte : Jusqu'à 8 192 tokens
Licence : Usage commercial autorisé
Trouver des informations enfouies dans des documents est un défi quotidien pour les travailleurs du savoir. Nemotron RAG apporte une intelligence multimodale à la recherche documentaire, traitant à la fois le texte et les images avec des analyses multilingues précises dans 26 langues.
Comment ça fonctionne
Le pipeline Nemotron RAG combine trois composants :
- Modèle d'embedding : convertit les documents en représentations vectorielles pour le stockage et la récupération
- Modèle de reclassement : reclasse les candidats potentiels dans l'ordre final en utilisant l'attention croisée
- Modèle de raisonnement : génère des réponses précises basées sur le contexte récupéré
Exemple concret : Agent de support informatique
NVIDIA a démontré comment ces modèles fonctionnent ensemble dans un agent de support informatique :
- Nemotron Nano 9B V2 : modèle de raisonnement principal pour générer des réponses
- Llama 3.2 EmbedQA 1B V2 : convertit les documents en embeddings vectoriels
- Llama 3.2 RerankQA 1B V2 : reclasse les documents récupérés par pertinence
Ces modèles permettent collectivement à l'agent de répondre avec précision aux requêtes des utilisateurs en exploitant la génération de langage, la récupération de documents et les capacités de reclassement.
Qui l'utilise
Cadence modélise les ressources de conception logique telles que les documents de micro-architecture, les contraintes et les garanties de vérification. Les ingénieurs peuvent poser des questions comme "Je veux étendre le contrôleur d'interruption pour prendre en charge un état de faible consommation, montrez-moi quelles sections de spécifications nécessitent des modifications" et obtenir instantanément les exigences pertinentes.
IBM teste ces modèles pour améliorer la recherche et le raisonnement dans la documentation technique.
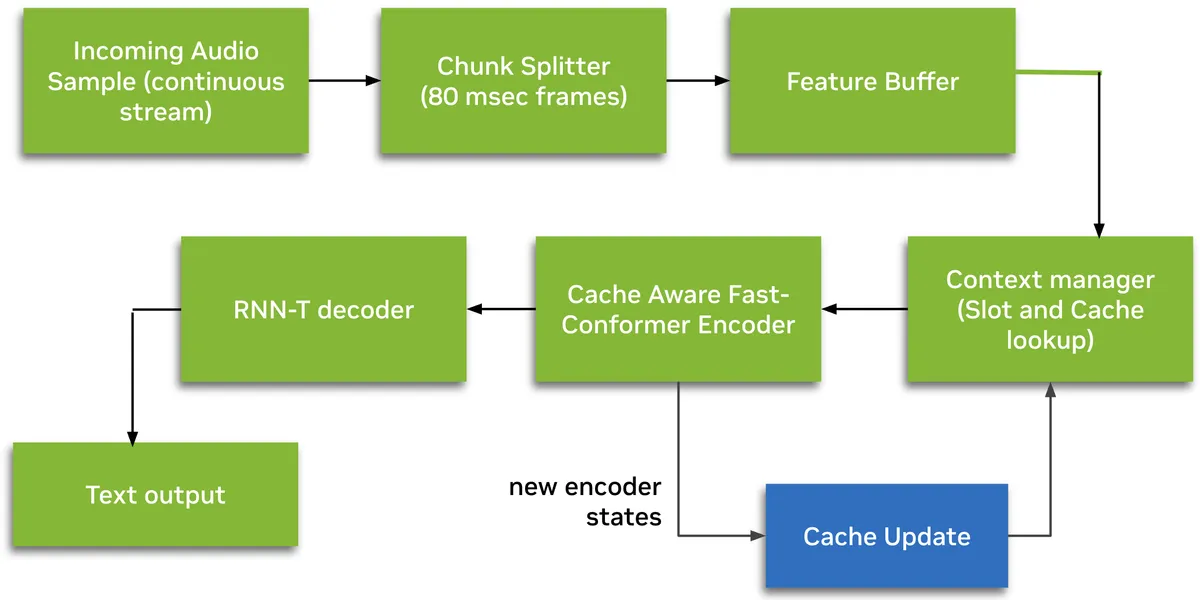
Nemotron Speech : Parlez à vos appareils comme jamais auparavant
Modèle : Nemotron-Speech-Streaming-En-0.6B
Paramètres : 600 millions
Architecture : Encodeur FastConformer avec gestion du cache + décodeur RNN-T
Latence : Streaming inférieur à 100 ms
Licence : Usage commercial autorisé
Nemotron Speech offre une reconnaissance vocale en temps réel 10 fois plus rapide que les modèles comparables et domine les classements ASR actuels.
Caractéristiques principales
- Architecture de streaming avec gestion du cache : traite uniquement les nouveaux segments audio tout en réutilisant le contexte d'encodeur mis en cache
- Modes de latence configurables à l'exécution : segments de 80 ms, 160 ms, 560 ms ou 1,12 s sans réentraînement
- Support natif de la ponctuation et des majuscules
- Entraîné sur 285 000 heures de données audio provenant du jeu de données NVIDIA Granary
Qui l'utilise
Bosch utilise déjà Nemotron Speech pour permettre aux conducteurs d'interagir avec les véhicules par commandes vocales. ServiceNow entraîne sa famille de modèles Apriel sur les ensembles de données Nemotron pour des performances multimodales rentables.
Attendez-vous à voir cette technologie dans les appareils domestiques intelligents, les systèmes de service client et les outils d'accessibilité tout au long de 2026.
Clara : Découverte de médicaments plus rapide et meilleurs soins de santé

La-Proteina : Conception de protéines au niveau atomique
ReaSyn v2 : Faisabilité de la synthèse de médicaments
KERMT : Tests de sécurité computationnels
RNAPro : Prédiction de formes 3D d'ARN
Ensemble de données : 455 000 structures protéiques synthétiques
Les nouveaux modèles Clara AI de NVIDIA visent à combler le fossé entre la découverte numérique et la médecine réelle. Bien que vous n'interagirez pas directement avec ces modèles, ils pourraient avoir un impact significatif sur vos soins de santé.
Détail des modèles
| Modèle | Fonction | Impact |
|---|---|---|
| La-Proteina | Concevoir de grandes protéines précises au niveau atomique | Étudier des maladies auparavant intraitables |
| ReaSyn v2 | Intégrer la faisabilité de synthèse dans la découverte | Éviter la recherche gaspillée sur des composés impraticables |
| KERMT | Prédire les interactions médicament-corps | Détecter les problèmes avant les essais cliniques coûteux |
| RNAPro | Prédire les formes 3D d'ARN | Permettre des thérapies personnalisées à base d'ARN |
En résumé : Les traitements pourraient atteindre les patients plus rapidement et à moindre coût.
Alpamayo : Rendre les voitures autonomes plus intelligentes

Modèle : Alpamayo-R1-10B
Paramètres : 10 milliards (8,2 milliards pour le backbone Cosmos Reason + 2,3 milliards pour l'expert d'action)
Données d'entraînement : Plus d'1 milliard d'images issues de 80 000 heures de conduite multi-caméras
Ensemble de données : Plus de 1 700 heures de données de conduite provenant de 25 pays
Licence : Non commerciale (recherche)
La nouvelle famille Alpamayo de NVIDIA accélérera le chemin vers des véhicules véritablement autonomes. Il s'agit du premier modèle VLA de raisonnement ouvert de l'industrie conçu pour la conduite autonome.
Innovation clé : Raisonnement en chaîne de pensée
Contrairement aux systèmes AV traditionnels qui se contentent de détecter des objets et de planifier des trajectoires, Alpamayo utilise le raisonnement en chaîne de pensée. Il peut :
- Traiter les entrées vidéo de plusieurs caméras
- Générer des trajectoires de conduite
- Expliquer la logique derrière chaque décision
Exemple de sortie : "Se décaler légèrement vers la gauche pour augmenter la distance avec les cônes de chantier qui empiètent sur la voie"
Ce qui est inclus
- Alpamayo 1 : Modèle VLA de raisonnement de 10 milliards sur Hugging Face
- AlpaSim : Framework de simulation de bout en bout open-source
- Physical AI Open Datasets : Plus de 1 700 heures couvrant des cas limites rares provenant de 25 pays et plus de 2 500 villes
Qui l'utilise
Lucid Motors, JLR, Uber et Berkeley DeepDrive utilisent Alpamayo pour développer des piles AV basées sur le raisonnement pour l'autonomie de niveau 4.
Cosmos : Apprendre aux robots à comprendre le monde physique

Cosmos Reason 2 : Versions de 2 et 8 milliards de paramètres
Fenêtre de contexte : 256 000 tokens (16 fois plus grande que la v1)
Architecture : Basée sur Qwen3-VL
Licence : Usage commercial autorisé (NVIDIA Open Model License)
Sur Hugging Face, la robotique est devenue le segment à la croissance la plus rapide, avec les modèles de NVIDIA en tête des téléchargements.
Famille de modèles Cosmos
| Modèle | Paramètres | Fonction |
|---|---|---|
| Cosmos Reason 2 | 2B / 8B | VLM de raisonnement d'IA physique pour robots et agents IA |
| Cosmos Transfer 2.5 | - | Transfert de style vidéo vers monde |
| Cosmos Predict 2.5 | 2B / 14B | Prédiction d'état futur sous forme de vidéo |
Caractéristiques principales de Cosmos Reason 2
- Compréhension spatio-temporelle améliorée avec précision d'horodatage
- Localisation de points 2D/3D et coordonnées de boîtes englobantes
- Sortie de données de trajectoire pour le contrôle robotique
- Support OCR pour lire le texte dans les environnements
- Raisonnement en chaîne de pensée avec balises
<think>
Isaac GR00T N1.6 : Modèle de base pour robots humanoïdes
Paramètres : 3 milliards
VLM de base : Variante Cosmos-Reason-2B
Architecture : VLA avec transformateur de diffusion à 32 couches
GR00T N1.6 est un modèle vision-langage-action ouvert spécialement conçu pour les robots humanoïdes. Il permet un contrôle complet du corps et utilise Cosmos Reason pour une meilleure compréhension contextuelle.
Qui l'utilise
- Franka Robotics, Humanoid et NEURA Robotics : simuler, entraîner et valider les comportements robotiques
- Salesforce, Hitachi, Uber et VAST Data : surveillance du trafic et productivité au travail
- Milestone : agents d'IA de vision pour la sécurité publique
Nemotron Safety : Construire une IA digne de confiance

Sécurité du contenu : Llama-3.1-Nemotron-Safety-Guard-8B-v3
Détection PII : Nemotron-PII (basé sur GLiNER)
Licence : Usage commercial autorisé
Pour les entreprises déployant l'IA, Nemotron Safety inclut des modèles de sécurité du contenu et une détection PII avec haute précision.
Composants
- Modèle de sécurité du contenu : support multilingue étendu avec nuances culturelles
- Détection PII : détecte les données personnelles sensibles avant qu'elles ne fuient
- Contrôle des sujets : gère les sujets que l'IA peut aborder
Qui l'utilise
- CrowdStrike, Cohesity et Fortinet : renforcer la sécurité des applications IA
- CodeRabbit : alimente les revues de code IA avec vitesse et précision améliorées
- Palantir : intégration dans le framework Ontology pour des agents IA spécialisés
Ce que cela signifie pour tous
Tous les modèles et données sont disponibles dès maintenant sur GitHub et Hugging Face, également sous forme de microservices NVIDIA NIM pour un déploiement évolutif.
Résumé des données ouvertes
| Ensemble de données | Taille | Contenu | |---------|------|---------|| | Tokens de langage | 10 billions | Raisonnement multilingue, codage, sécurité | | Trajectoires robotiques | 500 000 | Mouvement et manipulation robotiques | | Structures protéiques | 455 000 | Structures synthétiques pour l'IA biomédicale | | Données de capteurs de véhicules | 100 To | Conditions de conduite diverses | | Vidéo de conduite | Plus de 1 700 heures | Cas limites rares provenant de 25 pays |
Liens pour commencer
- Modèles Nemotron : developer.nvidia.com/nemotron
- Modèles Cosmos : github.com/nvidia-cosmos
- Alpamayo : developer.nvidia.com/drive/alpamayo
- Isaac GR00T : developer.nvidia.com/isaac/gr00t
Pour les utilisateurs réguliers, cette publication signifie de meilleurs assistants vocaux, une recherche documentaire plus intelligente, un développement de médicaments plus rapide, des voitures autonomes plus sûres et des robots plus performants. Ces technologies se retrouveront dans les produits grand public tout au long de 2026.
NVIDIA parie qu'en permettant à l'ensemble de l'écosystème IA de prospérer, ils vendront plus de GPU. Au vu des entreprises qui adoptent déjà ces technologies, ce pari est en train de porter ses fruits.
