

OpenAI lance GPT-5.2 : la première IA qui surpasse les professionnels du secteur
OpenAI vient de dévoiler GPT-5.2 et les résultats des tests de performance sont absolument impressionnants. Il ne s'agit pas simplement d'une mise à jour incrémentale. Pour la première fois, un modèle d'IA bat systématiquement les professionnels du secteur dans des tâches intellectuelles réelles.
Les résultats parlent d'eux-mêmes
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Travail intellectuel) | 70,9 % | 38,8 % |
| SWE-Bench Pro (Génie logiciel) | 55,6 % | 50,8 % |
| SWE-Bench Verified (Génie logiciel) | 80,0 % | 76,3 % |
| GPQA Diamond (Questions scientifiques) | 92,4 % | 88,1 % |
| CharXiv Reasoning (Figures scientifiques) | 88,7 % | 80,3 % |
| AIME 2025 (Mathématiques de compétition) | 100,0 % | 94,0 % |
| FrontierMath Tier 1-3 (Mathématiques avancées) | 40,3 % | 31,0 % |
| FrontierMath Tier 4 (Mathématiques avancées) | 14,6 % | 12,5 % |
| ARC-AGI-1 (Raisonnement abstrait) | 86,2 % | 72,8 % |
| ARC-AGI-2 (Raisonnement abstrait) | 52,9 % | 17,6 % |
Regardez ce bond sur ARC-AGI-2. De 17,6 % à 52,9 %. C'est une amélioration de 3x en matière de capacité de raisonnement abstrait authentique en une seule génération.
Le chiffre qui compte le plus
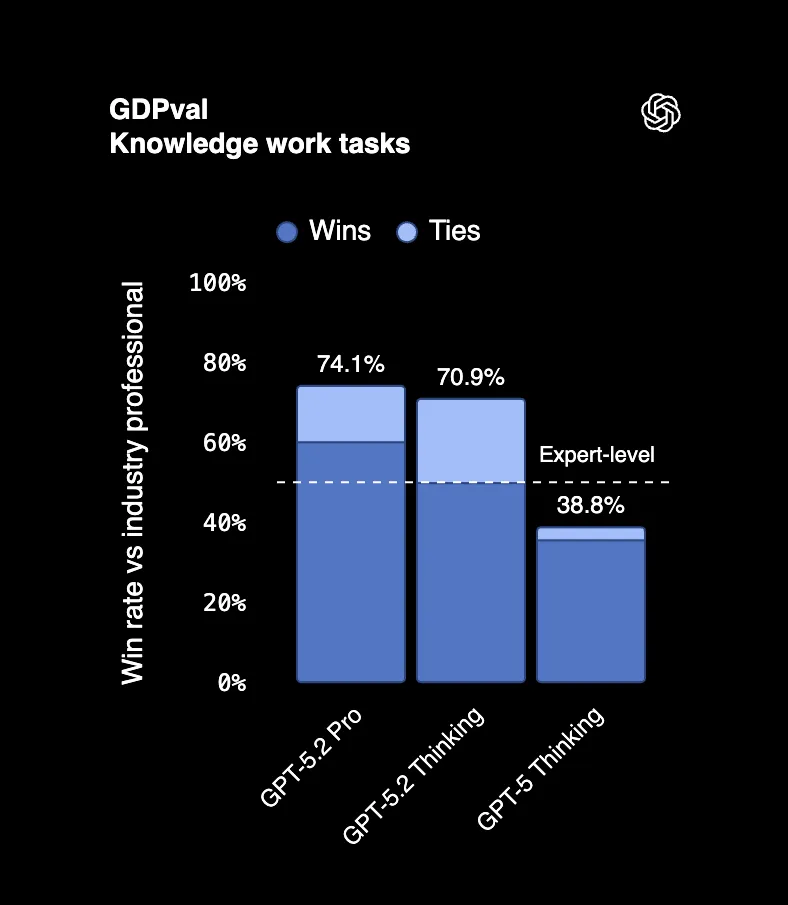
Sur GDPval, un test mesurant des tâches professionnelles réelles dans 44 métiers, GPT-5.2 Thinking bat ou égale les meilleurs professionnels du secteur dans 70,9 % des cas. On parle ici de créer des présentations, construire des feuilles de calcul, rédiger des rapports, le genre de tâches pour lesquelles les gens sont payés à six chiffres.
Un évaluateur examinant les résultats a déclaré qu'ils « semblent avoir été réalisés par une entreprise professionnelle avec du personnel ». Ce n'est pas une erreur. Un résultat d'IA confondu avec le travail d'une équipe entière.
Et voici le plus impressionnant : GPT-5.2 a produit ces résultats à 11 fois la vitesse et à moins de 1 % du coût des professionnels experts.
100 % aux compétitions de mathématiques
GPT-5.2 Thinking a obtenu 100 % à l'AIME 2025, une prestigieuse compétition de mathématiques qui met en difficulté la plupart des humains. Pas 99 %. Pas 98 %. Un score parfait.
Sur FrontierMath, qui teste les mathématiques de niveau expert avec lesquelles même les docteurs en mathématiques peinent, il a atteint 40,3 %, contre 31 % avec GPT-5.1.
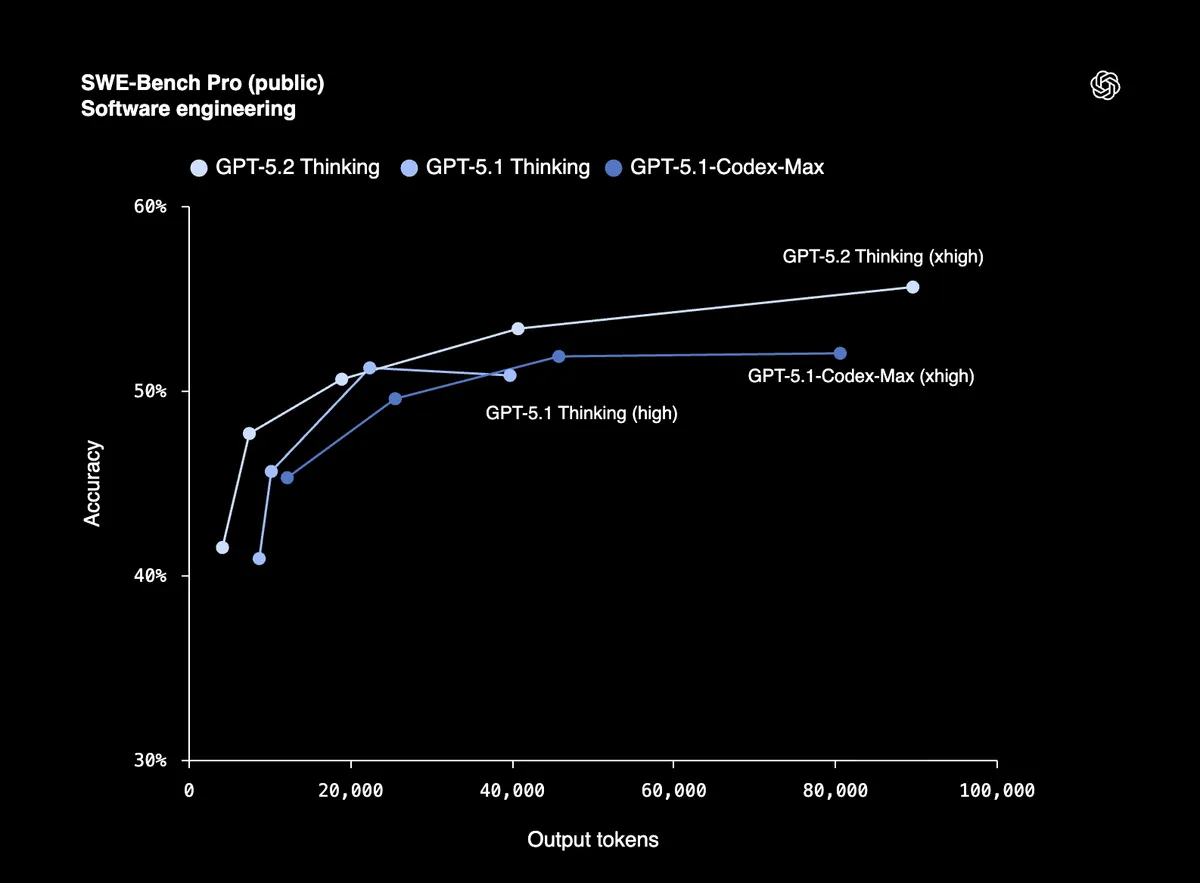
La programmation devient sérieuse
Un score de 80 % sur SWE-Bench Verified signifie que GPT-5.2 peut déboguer du code en production de manière fiable, implémenter des fonctionnalités et refactoriser de grandes bases de code avec un minimum d'assistance. SWE-Bench Pro teste le génie logiciel réel dans quatre langages de programmation, pas seulement Python.
Les premiers testeurs de Windsurf, JetBrains et Warp le qualifient de « plus grand bond en avant pour les modèles GPT en matière de codage agentique depuis GPT-5 ».
30 % d'hallucinations en moins
Ce point est important pour quiconque utilise l'IA professionnellement. GPT-5.2 Thinking produit 30 % de réponses avec erreurs en moins par rapport à GPT-5.1. Pour la recherche, l'analyse et la prise de décision, c'est une amélioration massive de la fiabilité.
La percée du contexte long
GPT-5.2 est le premier modèle à atteindre une précision proche de 100 % sur des tâches à contexte long allant jusqu'à 256 000 tokens. Cela signifie que vous pouvez lui fournir des bases de code entières, des contrats, des articles de recherche ou des transcriptions, et il maintient réellement la cohérence sur l'ensemble.
Les modèles précédents perdaient le fil à mi-chemin. GPT-5.2 ne le fait pas.
Une vision qui fonctionne vraiment
Les taux d'erreur sur le raisonnement graphique et la compréhension des interfaces logicielles ont été réduits d'environ la moitié. Le modèle peut maintenant interpréter avec précision les tableaux de bord, les diagrammes techniques et les captures d'écran, ce qui le rend véritablement utile pour les tâches d'analyse visuelle.

Ce que cela signifie pour vous
Si vous payez déjà pour ChatGPT Plus ou Pro, GPT-5.2 est en cours de déploiement. La tarification de l'API est de 1,75 $ par million de tokens en entrée et 14 $ par million de tokens en sortie, avec une réduction de 90 % sur les entrées en cache.
L'utilisateur moyen de ChatGPT Enterprise rapporte déjà économiser 40 à 60 minutes par jour. Les utilisateurs intensifs affirment gagner plus de 10 heures par semaine. Avec GPT-5.2, ces chiffres ne feront qu'augmenter.
Conclusion
GPT-5.2 n'est pas simplement meilleur. Il franchit des seuils que nous pensions être à des années de distance. Des scores parfaits aux compétitions de mathématiques. Battre les professionnels dans leur propre métier. Une compréhension quasi parfaite du contexte long.
Nous assistons en temps réel à la réduction de l'écart entre l'assistance par IA et la capacité de l'IA.
