
Al CES 2026, NVIDIA ha annunciato quello che potrebbe essere il più significativo rilascio open-source di IA fino ad oggi. L'azienda ha svelato nuovi modelli, dataset e strumenti che spaziano dal riconoscimento vocale alla scoperta di farmaci.
La portata è notevole:
- 10 trilioni di token di addestramento linguistico
- 500.000 traiettorie robotiche
- 455.000 strutture proteiche
- 100 terabyte di dati sensoriali da veicoli
Importanti aziende tra cui Bosch, Salesforce, Uber, Palantir e CrowdStrike stanno già costruendo su queste tecnologie.
Nemotron RAG: Ricerca Documenti più Intelligente

Modello di Embedding: Llama-Nemotron-Embed-VL-1B-V2 (1,7B parametri)
Modello di Reranking: Llama-Nemotron-Rerank-VL-1B-V2 (1,7B parametri)
Disponibile Anche: Modello di embedding solo testo da 8B parametri
Lunghezza Contesto: Fino a 8.192 token
Licenza: Uso commerciale consentito
Trovare informazioni sepolte nei documenti è una lotta quotidiana per i knowledge worker. Nemotron RAG porta l'intelligenza multimodale alla ricerca di documenti, elaborando sia testo che immagini con approfondimenti multilingue accurati in 26 lingue.
Come Funziona
La pipeline Nemotron RAG combina tre componenti:
- Modello di Embedding: converte i documenti in rappresentazioni vettoriali per l'archiviazione e il recupero
- Modello di Reranking: riordina i potenziali candidati in ordine finale utilizzando la cross-attention
- Modello di Ragionamento: genera risposte accurate basate sul contesto recuperato
Esempio Pratico: Agente Help Desk IT
NVIDIA ha dimostrato come questi modelli lavorano insieme in un agente Help Desk IT:
- Nemotron Nano 9B V2: modello di ragionamento primario per generare risposte
- Llama 3.2 EmbedQA 1B V2: converte i documenti in embedding vettoriali
- Llama 3.2 RerankQA 1B V2: riordina i documenti recuperati per rilevanza
Questi modelli consentono collettivamente all'agente di rispondere accuratamente alle domande degli utenti sfruttando la generazione del linguaggio, il recupero dei documenti e le capacità di reranking.
Chi lo Sta Usando
Cadence modella risorse di progettazione logica come documenti di micro-architettura, vincoli e collateral di verifica. Gli ingegneri possono fare domande come "Voglio estendere il controller di interrupt per supportare uno stato a basso consumo, mostrami quali sezioni delle specifiche necessitano modifiche" e far emergere istantaneamente i requisiti pertinenti.
IBM sta sperimentando questi modelli per migliorare la ricerca e il ragionamento nella documentazione tecnica.
Nemotron Speech: Parla ai Tuoi Dispositivi Come Mai Prima
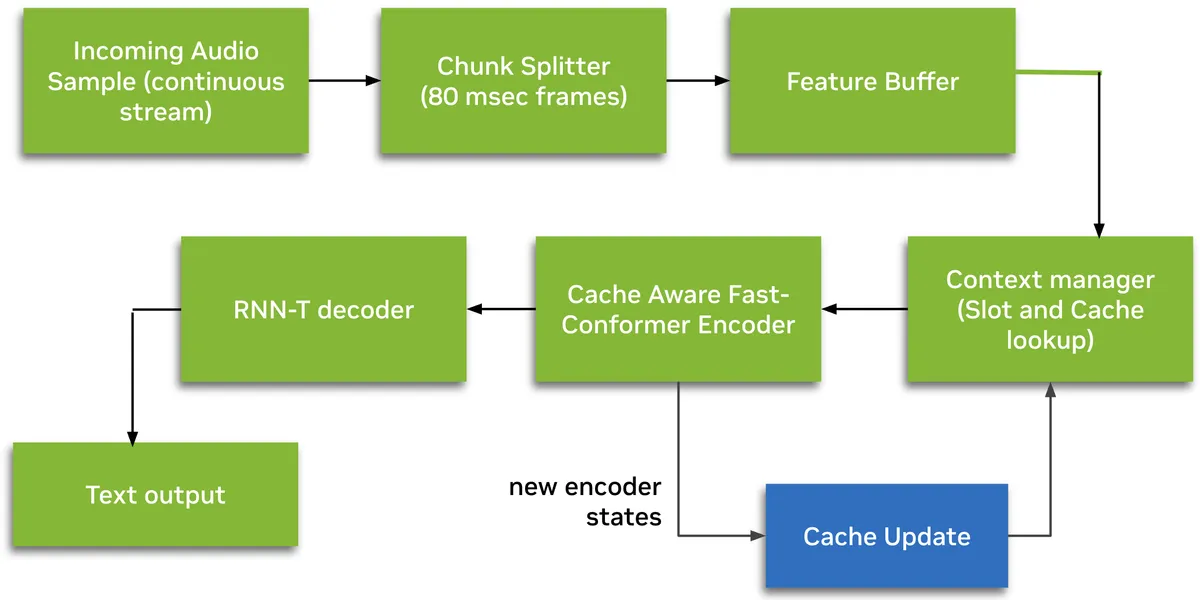
Modello: Nemotron-Speech-Streaming-En-0.6B
Parametri: 600M
Architettura: Encoder FastConformer cache-aware + decoder RNN-T
Latenza: Streaming sotto i 100ms
Licenza: Uso commerciale consentito
Nemotron Speech offre riconoscimento vocale in tempo reale che funziona 10 volte più velocemente rispetto a modelli comparabili e si posiziona in cima alle attuali classifiche ASR.
Caratteristiche Principali
- Architettura di streaming cache-aware: elabora solo nuovi frammenti audio riutilizzando il contesto dell'encoder memorizzato
- Modalità di latenza configurabili a runtime: frammenti da 80ms, 160ms, 560ms o 1,12s senza riaddestramento
- Supporto nativo per punteggiatura e maiuscole
- Addestrato su 285.000 ore di dati audio dal dataset NVIDIA Granary
Chi lo Sta Usando
Bosch sta già utilizzando Nemotron Speech per consentire ai conducenti di interagire con i veicoli tramite comandi vocali. ServiceNow addestra la sua famiglia di modelli Apriel sui dataset Nemotron per prestazioni multimodali economicamente efficienti.
Aspettatevi questa tecnologia in dispositivi per la casa intelligente, sistemi di assistenza clienti e strumenti di accessibilità per tutto il 2026.
Clara: Scoperta di Farmaci più Veloce e Assistenza Sanitaria Migliore

La-Proteina: Progettazione di proteine a livello atomico
ReaSyn v2: Fattibilità della sintesi farmacologica
KERMT: Test di sicurezza computazionale
RNAPro: Previsione della forma 3D dell'RNA
Dataset: 455.000 strutture proteiche sintetiche
I nuovi modelli Clara AI di NVIDIA mirano a colmare il divario tra scoperta digitale e medicina del mondo reale. Anche se non interagirai direttamente con questi modelli, potrebbero avere un impatto significativo sulla tua assistenza sanitaria.
Panoramica dei Modelli
| Modello | Funzione | Impatto |
|---|---|---|
| La-Proteina | Progetta proteine grandi e precise a livello atomico | Studio di malattie precedentemente non trattabili |
| ReaSyn v2 | Incorpora la fattibilità di sintesi nella scoperta | Previene ricerche sprecate su composti impraticabili |
| KERMT | Prevede le interazioni farmaco-corpo | Individua problemi prima di costose sperimentazioni cliniche |
| RNAPro | Prevede le forme 3D dell'RNA | Abilita terapie personalizzate basate sull'RNA |
In sintesi: I trattamenti potrebbero raggiungere i pazienti più velocemente e a costi inferiori.
Alpamayo: Rendere le Auto a Guida Autonoma più Intelligenti

Modello: Alpamayo-R1-10B
Parametri: 10 miliardi (8,2B backbone Cosmos Reason + 2,3B esperto di azioni)
Dati di Addestramento: Oltre 1 miliardo di immagini da 80.000 ore di guida multi-camera
Dataset: Oltre 1.700 ore di dati di guida da 25 paesi
Licenza: Non commerciale (ricerca)
La nuova famiglia Alpamayo di NVIDIA accelererà il percorso verso veicoli veramente autonomi. Questo è il primo modello VLA di ragionamento aperto del settore progettato per la guida autonoma.
Innovazione Chiave: Ragionamento Chain-of-Thought
A differenza dei sistemi AV tradizionali che rilevano solo oggetti e pianificano percorsi, Alpamayo utilizza il ragionamento chain-of-thought. Può:
- Elaborare input video da più telecamere
- Generare traiettorie di guida
- Spiegare la logica dietro ogni decisione
Esempio di output: "Spostati leggermente a sinistra per aumentare la distanza dai coni di costruzione che invadono la corsia"
Cosa è Incluso
- Alpamayo 1: modello VLA di ragionamento da 10B su Hugging Face
- AlpaSim: framework di simulazione end-to-end open-source
- Physical AI Open Datasets: oltre 1.700 ore che coprono casi limite rari da 25 paesi e oltre 2.500 città
Chi lo Sta Usando
Lucid Motors, JLR, Uber e Berkeley DeepDrive stanno utilizzando Alpamayo per sviluppare stack AV basati sul ragionamento per l'autonomia di Livello 4.
Cosmos: Insegnare ai Robot a Comprendere il Mondo Fisico

Cosmos Reason 2: Versioni da 2B e 8B parametri
Finestra di Contesto: 256K token (16 volte più grande della v1)
Architettura: Basata su Qwen3-VL
Licenza: Uso commerciale consentito (NVIDIA Open Model License)
Su Hugging Face, la robotica è diventata il segmento in più rapida crescita, con i modelli di NVIDIA in testa ai download.
Famiglia di Modelli Cosmos
| Modello | Parametri | Funzione |
|---|---|---|
| Cosmos Reason 2 | 2B / 8B | VLM di ragionamento per IA fisica per robot e agenti IA |
| Cosmos Transfer 2.5 | - | Trasferimento di stile video-mondo |
| Cosmos Predict 2.5 | 2B / 14B | Previsione dello stato futuro come video |
Caratteristiche Principali di Cosmos Reason 2
- Comprensione spazio-temporale migliorata con precisione del timestamp
- Localizzazione di punti 2D/3D e coordinate di bounding box
- Output di dati di traiettoria per il controllo robotico
- Supporto OCR per leggere testo negli ambienti
- Ragionamento chain-of-thought con tag
<think>
Isaac GR00T N1.6: Modello Foundation per Robot Umanoidi
Parametri: 3B
VLM Base: Variante Cosmos-Reason-2B
Architettura: VLA con trasformatore di diffusione a 32 strati
GR00T N1.6 è un modello vision-language-action aperto appositamente costruito per robot umanoidi. Sblocca il controllo completo del corpo e utilizza Cosmos Reason per una migliore comprensione contestuale.
Chi lo Sta Usando
- Franka Robotics, Humanoid e NEURA Robotics: simulano, addestrano e validano comportamenti robotici
- Salesforce, Hitachi, Uber e VAST Data: monitoraggio del traffico e produttività sul posto di lavoro
- Milestone: agenti IA di visione per la sicurezza pubblica
Nemotron Safety: Costruire IA Affidabile

Sicurezza dei Contenuti: Llama-3.1-Nemotron-Safety-Guard-8B-v3
Rilevamento PII: Nemotron-PII (basato su GLiNER)
Licenza: Uso commerciale consentito
Per le aziende che implementano l'IA, Nemotron Safety include modelli di sicurezza dei contenuti e rilevamento PII con alta precisione.
Componenti
- Modello di Sicurezza dei Contenuti: supporto multilingue ampliato con sfumature culturali
- Rilevamento PII: rileva dati personali sensibili prima che vengano divulgati
- Controllo degli Argomenti: gestisce quali argomenti l'IA può discutere
Chi lo Sta Usando
- CrowdStrike, Cohesity e Fortinet: rafforzano la sicurezza delle applicazioni IA
- CodeRabbit: alimenta revisioni di codice IA con velocità e precisione migliorate
- Palantir: integrazione nel framework Ontology per agenti IA specializzati
Cosa Significa Questo per Tutti
Tutti i modelli e i dati sono disponibili ora su GitHub e Hugging Face, anche come microservizi NVIDIA NIM per implementazioni scalabili.
Riepilogo Dati Aperti
| Dataset | Dimensione | Contenuto | |---------|------|---------|| | Token linguistici | 10 trilioni | Ragionamento multilingue, codifica, sicurezza | | Traiettorie robotiche | 500.000 | Movimento e manipolazione robotica | | Strutture proteiche | 455.000 | Strutture sintetiche per IA biomedica | | Dati sensoriali veicoli | 100 TB | Diverse condizioni di guida | | Video di guida | Oltre 1.700 ore | Casi limite rari da 25 paesi |
Link per Iniziare
- Modelli Nemotron: developer.nvidia.com/nemotron
- Modelli Cosmos: github.com/nvidia-cosmos
- Alpamayo: developer.nvidia.com/drive/alpamayo
- Isaac GR00T: developer.nvidia.com/isaac/gr00t
Per gli utenti comuni, questo rilascio significa assistenti vocali migliori, ricerca documenti più intelligente, sviluppo di farmaci più veloce, auto a guida autonoma più sicure e robot più capaci. Queste tecnologie si diffonderanno nei prodotti di consumo per tutto il 2026.
NVIDIA scommette che abilitando l'intero ecosistema IA, venderà più GPU. Basandosi sulle aziende che stanno già adottando queste tecnologie, quella scommessa sta dando i suoi frutti.
