

OpenAI Rilascia GPT-5.2: La Prima IA Che Supera i Professionisti del Settore
OpenAI ha appena lanciato GPT-5.2 e i benchmark sono assolutamente straordinari. Non si tratta solo di un altro aggiornamento incrementale. Per la prima volta in assoluto, un modello di IA batte costantemente i professionisti del settore nel lavoro intellettuale del mondo reale.
I Benchmark Parlano da Soli
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Lavoro intellettuale) | 70,9% | 38,8% |
| SWE-Bench Pro (Ingegneria del software) | 55,6% | 50,8% |
| SWE-Bench Verified (Ingegneria del software) | 80,0% | 76,3% |
| GPQA Diamond (Domande scientifiche) | 92,4% | 88,1% |
| CharXiv Reasoning (Figure scientifiche) | 88,7% | 80,3% |
| AIME 2025 (Matematica competitiva) | 100,0% | 94,0% |
| FrontierMath Tier 1-3 (Matematica avanzata) | 40,3% | 31,0% |
| FrontierMath Tier 4 (Matematica avanzata) | 14,6% | 12,5% |
| ARC-AGI-1 (Ragionamento astratto) | 86,2% | 72,8% |
| ARC-AGI-2 (Ragionamento astratto) | 52,9% | 17,6% |
Guardate quel salto su ARC-AGI-2. Dal 17,6% al 52,9%. Si tratta di un miglioramento di 3 volte nella capacità di ragionamento astratto genuino in una sola generazione.
Il Numero Che Conta di Più
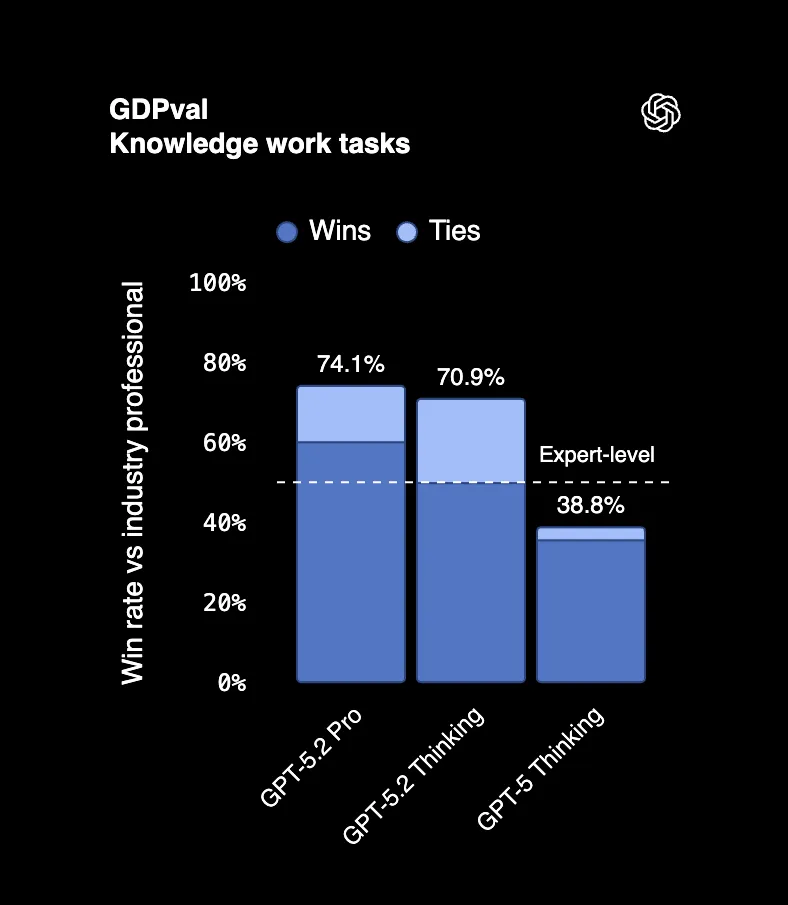
Su GDPval, un benchmark che misura compiti professionali reali in 44 occupazioni, GPT-5.2 Thinking batte o pareggia i migliori professionisti del settore il 70,9% delle volte. Parliamo di creare presentazioni, costruire fogli di calcolo, scrivere report, le cose per cui le persone vengono pagate sei cifre.
Un giudice che ha esaminato i risultati ha detto che "sembra essere stato fatto da un'azienda professionale con personale dedicato". Non è un errore di battitura. Un output di IA viene scambiato per il lavoro di un intero team.
E questo è il punto cruciale: GPT-5.2 ha prodotto questi risultati a 11 volte la velocità e meno dell'1% del costo dei professionisti esperti.
100% nella Matematica Competitiva
GPT-5.2 Thinking ha ottenuto il 100% su AIME 2025, una prestigiosa competizione di matematica che mette in difficoltà la maggior parte degli esseri umani. Non il 99%. Non il 98%. Punteggio perfetto.
Su FrontierMath, che testa la matematica a livello esperto con cui anche i matematici con dottorato faticano, ha raggiunto il 40,3%, rispetto al 31% con GPT-5.1.
La Programmazione È Diventata Seria
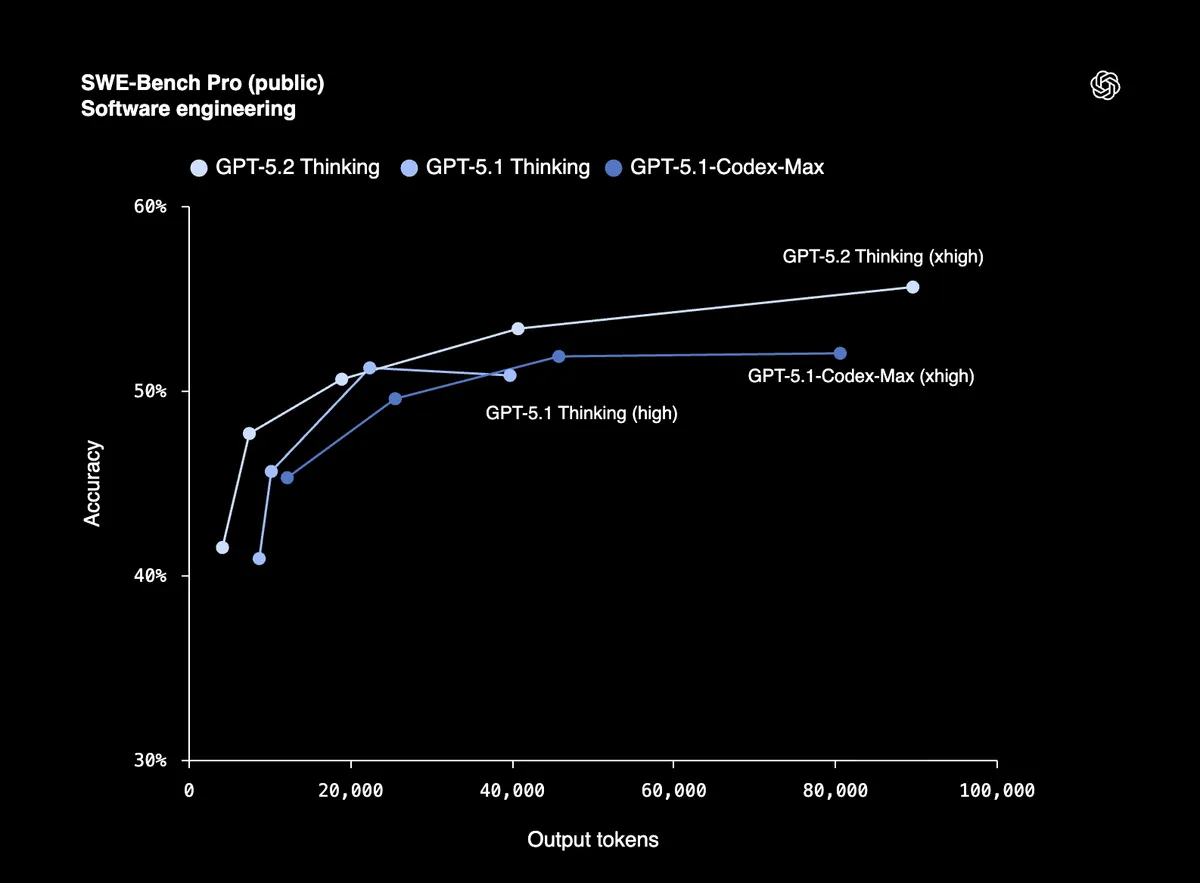
Un punteggio dell'80% su SWE-Bench Verified significa che GPT-5.2 può fare debug affidabile del codice di produzione, implementare funzionalità e rifattorizzare grandi codebase con un supporto minimo. SWE-Bench Pro testa l'ingegneria del software nel mondo reale su quattro linguaggi di programmazione, non solo Python.
I primi tester di Windsurf, JetBrains e Warp lo definiscono "il più grande salto per i modelli GPT nella programmazione agentica da GPT-5."
30% in Meno di Allucinazioni
Questo aspetto è importante per chiunque utilizzi l'IA professionalmente. GPT-5.2 Thinking produce il 30% in meno di risposte con errori rispetto a GPT-5.1. Per la ricerca, l'analisi e il processo decisionale, si tratta di un enorme aumento dell'affidabilità.
La Svolta del Contesto Lungo
GPT-5.2 è il primo modello a raggiungere un'accuratezza quasi del 100% su attività con contesto lungo fino a 256k token. Ciò significa che puoi fornirgli intere codebase, contratti, articoli di ricerca o trascrizioni, e mantiene effettivamente la coerenza su tutto.
I modelli precedenti perdevano il filo a metà strada. GPT-5.2 no.
Una Visione Che Funziona Davvero
I tassi di errore sul ragionamento dei grafici e sulla comprensione delle interfacce software sono stati ridotti circa della metà. Il modello ora può interpretare accuratamente dashboard, diagrammi tecnici e screenshot, rendendolo genuinamente utile per compiti di analisi visiva.

Cosa Significa per Te
Se stai già pagando per ChatGPT Plus o Pro, GPT-5.2 è in fase di distribuzione ora. Il prezzo dell'API è di 1,75 dollari per milione di token in input e 14 dollari per milione di token in output, con uno sconto del 90% sugli input memorizzati nella cache.
L'utente medio di ChatGPT Enterprise riporta già un risparmio di 40-60 minuti al giorno. Gli utenti intensivi dichiarano oltre 10 ore a settimana. Con GPT-5.2, questi numeri sono destinati solo ad aumentare.
La Conclusione
GPT-5.2 non è solo migliore. Sta superando soglie che pensavamo fossero lontane anni. Punteggi perfetti nelle competizioni di matematica. Battere i professionisti nel loro stesso lavoro. Comprensione del contesto lungo quasi perfetta.
Stiamo assistendo al divario tra assistenza IA e capacità IA che si chiude in tempo reale.
