

OpenAI、GPT-5.2をリリース: 業界プロフェッショナルを上回る初のAI
OpenAIがGPT-5.2をリリースし、そのベンチマークは驚異的です。これは単なる段階的なアップデートではありません。史上初めて、AIモデルが実世界の知識労働において、業界のプロフェッショナルを一貫して上回るようになりました。
ベンチマークが物語る性能
| ベンチマーク | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
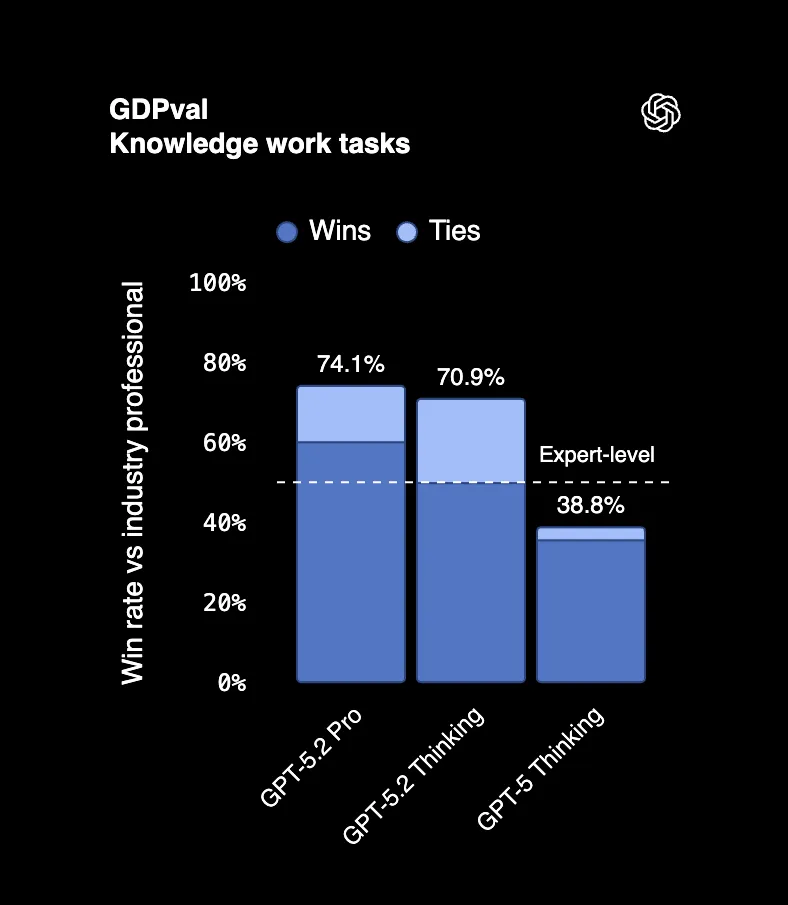
| GDPval (知識労働) | 70.9% | 38.8% |
| SWE-Bench Pro (ソフトウェアエンジニアリング) | 55.6% | 50.8% |
| SWE-Bench Verified (ソフトウェアエンジニアリング) | 80.0% | 76.3% |
| GPQA Diamond (科学的質問) | 92.4% | 88.1% |
| CharXiv Reasoning (科学的図表) | 88.7% | 80.3% |
| AIME 2025 (競技数学) | 100.0% | 94.0% |
| FrontierMath Tier 1-3 (高度な数学) | 40.3% | 31.0% |
| FrontierMath Tier 4 (高度な数学) | 14.6% | 12.5% |
| ARC-AGI-1 (抽象的推論) | 86.2% | 72.8% |
| ARC-AGI-2 (抽象的推論) | 52.9% | 17.6% |
ARC-AGI-2の飛躍に注目してください。17.6%から52.9%へ。これは真の抽象的推論能力が1世代で3倍向上したことを意味します。
最も重要な数値
44の職業にわたる実際の専門的タスクを測定するベンチマークであるGDPvalにおいて、GPT-5.2 Thinkingは70.9%の確率でトップ業界プロフェッショナルと同等かそれ以上の成果を出しています。プレゼンテーション作成、スプレッドシート構築、レポート作成など、人々が6桁の報酬を得て行っている仕事のことです。
出力をレビューしたある審査員は、「スタッフを抱えるプロフェッショナル企業によって作成されたように見える」と述べました。これは誤植ではありません。AIの出力が、チーム全体の仕事と間違えられているのです。
さらに驚くべきことに、GPT-5.2はこれらの出力を専門家の11倍の速度で、コストは1%未満で生成しました。
競技数学で100%達成
GPT-5.2 Thinkingは、ほとんどの人間を困惑させる権威ある数学コンテストである**AIME 2025で100%**のスコアを記録しました。99%でも98%でもなく、満点です。
博士号を持つ数学者でさえ苦戦する専門レベルの数学をテストするFrontierMathでは、GPT-5.1の31%から40.3%に向上しました。
コーディングが本格化
SWE-Bench Verifiedで80%のスコアを獲得したということは、GPT-5.2が本番コードのデバッグ、機能実装、大規模コードベースのリファクタリングを最小限の手助けで確実に実行できることを意味します。SWE-Bench Proは、Pythonだけでなく4つのプログラミング言語にわたる実世界のソフトウェアエンジニアリングをテストします。
Windsurf、JetBrains、Warpの初期テスターたちは、これを「GPT-5以来、エージェント型コーディングにおけるGPTモデルの最大の飛躍」と呼んでいます。
ハルシネーションが30%減少
これは、AIを業務で使用している人にとって重要です。GPT-5.2 Thinkingは、GPT-5.1と比較してエラーを含む応答が30%減少しています。研究、分析、意思決定において、これは信頼性の大幅な向上を意味します。
長文コンテキストのブレークスルー
GPT-5.2は、256kトークンまでの長文コンテキストタスクでほぼ100%の精度を達成した初のモデルです。つまり、コードベース全体、契約書、研究論文、トランスクリプトを入力しても、すべてにわたって一貫性を維持できるということです。
以前のモデルは途中で文脈を見失っていました。GPT-5.2はそうではありません。
実用的なビジョン機能
チャート推論とソフトウェアインターフェース理解のエラー率が約半分に削減されました。このモデルは、ダッシュボード、技術図、スクリーンショットを正確に解釈できるようになり、視覚分析タスクにおいて真に有用になりました。

あなたにとっての意味
すでにChatGPT PlusまたはProに課金している場合、GPT-5.2は現在展開中です。API価格は入力トークン100万あたり1.75ドル、出力トークン100万あたり14ドルで、キャッシュされた入力には90%の割引があります。
平均的なChatGPT Enterpriseユーザーは、すでに1日あたり40〜60分の節約を報告しています。ヘビーユーザーは週に10時間以上と主張しています。GPT-5.2により、これらの数字はさらに上昇するでしょう。
結論
GPT-5.2は単に優れているだけではありません。数年先だと思われていた閾値を越えています。数学コンテストでの満点。プロフェッショナルを彼ら自身の仕事で打ち負かす。ほぼ完璧な長文コンテキスト理解。
私たちは、AIアシスタンスとAI能力の間のギャップがリアルタイムで縮まるのを目撃しています。
