
Na CES 2026, a NVIDIA anunciou o que pode ser o lançamento de IA de código aberto mais significativo até hoje. A empresa revelou novos modelos, conjuntos de dados e ferramentas que abrangem desde reconhecimento de fala até descoberta de medicamentos.
A escala é notável:
- 10 trilhões de tokens de treinamento de linguagem
- 500.000 trajetórias de robótica
- 455.000 estruturas de proteínas
- 100 terabytes de dados de sensores de veículos
Grandes empresas incluindo Bosch, Salesforce, Uber, Palantir e CrowdStrike já estão construindo sobre essas tecnologias.
Nemotron RAG: Busca de Documentos Mais Inteligente

Modelo de Embedding: Llama-Nemotron-Embed-VL-1B-V2 (1,7B parâmetros)
Modelo de Reranking: Llama-Nemotron-Rerank-VL-1B-V2 (1,7B parâmetros)
Também Disponível: Modelo de embedding somente texto de 8B parâmetros
Comprimento de Contexto: Até 8.192 tokens
Licença: Uso comercial permitido
Encontrar informações enterradas em documentos é uma luta diária para trabalhadores do conhecimento. O Nemotron RAG traz inteligência multimodal para busca de documentos, processando tanto texto quanto imagens com insights multilíngues precisos em 26 idiomas.
Como Funciona
O pipeline Nemotron RAG combina três componentes:
- Modelo de Embedding: converte documentos em representações vetoriais para armazenamento e recuperação
- Modelo de Reranking: reordena candidatos potenciais em ordem final usando atenção cruzada
- Modelo de Raciocínio: gera respostas precisas baseadas no contexto recuperado
Exemplo do Mundo Real: Agente de Help Desk de TI
A NVIDIA demonstrou como esses modelos trabalham juntos em um agente de Help Desk de TI:
- Nemotron Nano 9B V2: modelo de raciocínio primário para gerar respostas
- Llama 3.2 EmbedQA 1B V2: converte documentos em embeddings vetoriais
- Llama 3.2 RerankQA 1B V2: reordena documentos recuperados por relevância
Esses modelos coletivamente permitem que o agente responda consultas de usuários com precisão aproveitando geração de linguagem, recuperação de documentos e capacidades de reranking.
Quem Está Usando
A Cadence modela ativos de design lógico como documentos de microarquitetura, restrições e garantias de verificação. Engenheiros podem fazer perguntas como "Quero estender o controlador de interrupção para suportar um estado de baixo consumo, mostre-me quais seções da especificação precisam de mudanças" e instantaneamente encontrar requisitos relevantes.
A IBM está pilotando esses modelos para melhorar busca e raciocínio em documentação técnica.
Nemotron Speech: Converse com Seus Dispositivos Como Nunca Antes
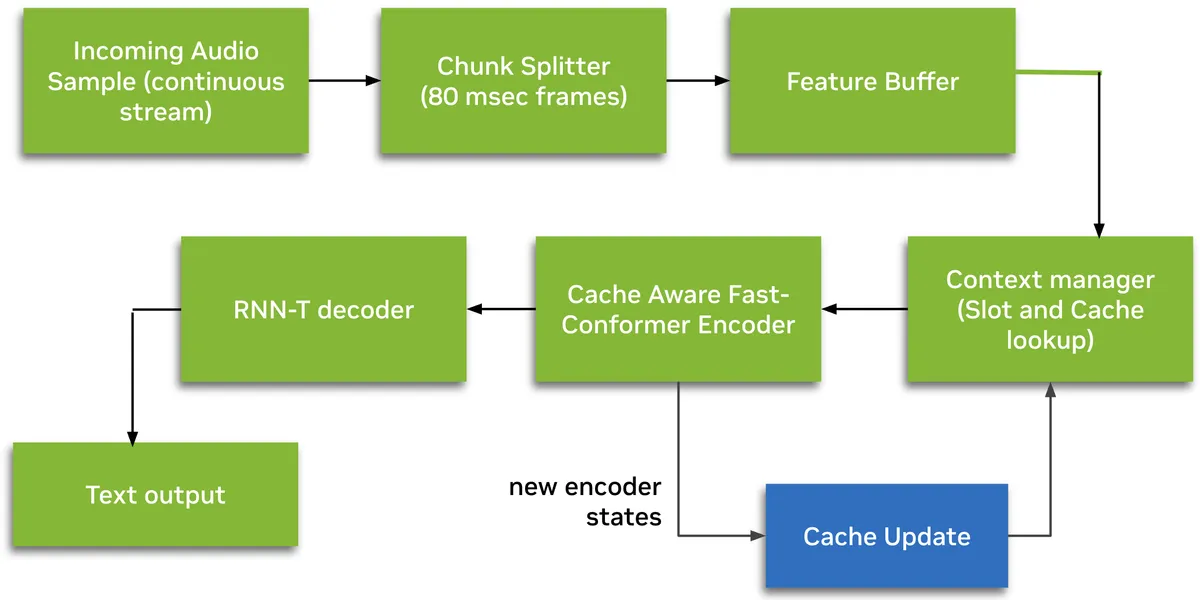
Modelo: Nemotron-Speech-Streaming-En-0.6B
Parâmetros: 600M
Arquitetura: Codificador FastConformer com cache + decodificador RNN-T
Latência: Streaming abaixo de 100ms
Licença: Uso comercial permitido
O Nemotron Speech oferece reconhecimento de fala em tempo real que performa 10x mais rápido que modelos comparáveis e lidera os rankings atuais de ASR.
Recursos Principais
- Arquitetura de streaming com cache: processa apenas novos trechos de áudio enquanto reutiliza contexto de codificador em cache
- Modos de latência configuráveis em tempo de execução: trechos de 80ms, 160ms, 560ms ou 1,12s sem retreinamento
- Suporte nativo a pontuação e capitalização
- Treinado em 285.000 horas de dados de áudio do conjunto de dados NVIDIA Granary
Quem Está Usando
A Bosch já está usando o Nemotron Speech para permitir que motoristas interajam com veículos através de comandos de voz. A ServiceNow treina sua família de modelos Apriel em conjuntos de dados Nemotron para desempenho multimodal econômico.
Espere essa tecnologia em dispositivos domésticos inteligentes, sistemas de atendimento ao cliente e ferramentas de acessibilidade ao longo de 2026.
Clara: Descoberta de Medicamentos Mais Rápida e Melhor Assistência à Saúde

La-Proteina: Design de proteínas em nível atômico
ReaSyn v2: Viabilidade de síntese de medicamentos
KERMT: Testes de segurança computacionais
RNAPro: Predição de forma 3D de RNA
Conjunto de Dados: 455.000 estruturas de proteínas sintéticas
Os novos modelos Clara AI da NVIDIA visam preencher a lacuna entre descoberta digital e medicina do mundo real. Embora você não interaja diretamente com esses modelos, eles podem impactar significativamente sua assistência à saúde.
Detalhamento dos Modelos
| Modelo | Função | Impacto |
|---|---|---|
| La-Proteina | Projetar proteínas grandes e precisas em nível atômico | Estudar doenças anteriormente intratáveis |
| ReaSyn v2 | Incorporar viabilidade de síntese na descoberta | Prevenir pesquisa desperdiçada em compostos impraticáveis |
| KERMT | Prever interações medicamento-corpo | Detectar problemas antes de ensaios clínicos caros |
| RNAPro | Prever formas 3D de RNA | Permitir terapias personalizadas baseadas em RNA |
Resumindo: Tratamentos podem chegar aos pacientes mais rápido e a menor custo.
Alpamayo: Tornando Carros Autônomos Mais Inteligentes

Modelo: Alpamayo-R1-10B
Parâmetros: 10 bilhões (8,2B backbone Cosmos Reason + 2,3B especialista em ação)
Dados de Treinamento: Mais de 1 bilhão de imagens de 80.000 horas de direção com múltiplas câmeras
Conjunto de Dados: Mais de 1.700 horas de dados de direção de 25 países
Licença: Não comercial (pesquisa)
A nova família Alpamayo da NVIDIA acelerará o caminho para veículos verdadeiramente autônomos. Este é o primeiro modelo VLA de raciocínio aberto da indústria projetado para direção autônoma.
Inovação Principal: Raciocínio em Cadeia de Pensamento
Ao contrário de sistemas AV tradicionais que apenas detectam objetos e planejam rotas, o Alpamayo usa raciocínio em cadeia de pensamento. Ele pode:
- Processar entrada de vídeo de múltiplas câmeras
- Gerar trajetórias de direção
- Explicar a lógica por trás de cada decisão
Exemplo de saída: "Desviar para a esquerda para aumentar a distância dos cones de construção invadindo a faixa"
O Que Está Incluído
- Alpamayo 1: modelo VLA de raciocínio de 10B no Hugging Face
- AlpaSim: framework de simulação de ponta a ponta de código aberto
- Conjuntos de Dados Abertos de IA Física: Mais de 1.700 horas cobrindo casos extremos raros de 25 países e mais de 2.500 cidades
Quem Está Usando
Lucid Motors, JLR, Uber e Berkeley DeepDrive estão usando o Alpamayo para desenvolver pilhas AV baseadas em raciocínio para autonomia Nível 4.
Cosmos: Ensinando Robôs a Entender o Mundo Físico

Cosmos Reason 2: Versões de 2B e 8B parâmetros
Janela de Contexto: 256K tokens (16x maior que v1)
Arquitetura: Baseado em Qwen3-VL
Licença: Uso comercial permitido (NVIDIA Open Model License)
No Hugging Face, robótica se tornou o segmento de crescimento mais rápido, com os modelos da NVIDIA liderando downloads.
Família de Modelos Cosmos
| Modelo | Parâmetros | Função |
|---|---|---|
| Cosmos Reason 2 | 2B / 8B | VLM de raciocínio de IA física para robôs e agentes de IA |
| Cosmos Transfer 2.5 | - | Transferência de estilo vídeo para mundo |
| Cosmos Predict 2.5 | 2B / 14B | Predição de estado futuro como vídeo |
Recursos Principais do Cosmos Reason 2
- Compreensão espaço-temporal aprimorada com precisão de timestamp
- Localização de pontos 2D/3D e coordenadas de caixa delimitadora
- Saída de dados de trajetória para controle robótico
- Suporte OCR para ler texto em ambientes
- Raciocínio em cadeia de pensamento com tags
<think>
Isaac GR00T N1.6: Modelo de Fundação para Robôs Humanoides
Parâmetros: 3B
VLM Base: Variante Cosmos-Reason-2B
Arquitetura: VLA com transformador de difusão de 32 camadas
GR00T N1.6 é um modelo de visão-linguagem-ação aberto construído especificamente para robôs humanoides. Ele desbloqueia controle de corpo completo e usa Cosmos Reason para melhor compreensão contextual.
Quem Está Usando
- Franka Robotics, Humanoid e NEURA Robotics , simulam, treinam e validam comportamentos de robôs
- Salesforce, Hitachi, Uber e VAST Data , monitoramento de tráfego e produtividade no local de trabalho
- Milestone , agentes de IA de visão para segurança pública
Nemotron Safety: Construindo IA Confiável

Segurança de Conteúdo: Llama-3.1-Nemotron-Safety-Guard-8B-v3
Detecção de PII: Nemotron-PII (baseado em GLiNER)
Licença: Uso comercial permitido
Para empresas implantando IA, o Nemotron Safety inclui modelos de segurança de conteúdo e detecção de PII com alta precisão.
Componentes
- Modelo de Segurança de Conteúdo: suporte multilíngue expandido com nuance cultural
- Detecção de PII: detecta dados pessoais sensíveis antes que vazem
- Controle de Tópicos: gerencia quais tópicos a IA pode discutir
Quem Está Usando
- CrowdStrike, Cohesity e Fortinet: fortalecem segurança de aplicações de IA
- CodeRabbit: alimenta revisões de código de IA com velocidade e precisão melhoradas
- Palantir: integrando ao framework Ontology para agentes de IA especializados
O Que Isso Significa para Todos
Todos os modelos e dados estão disponíveis agora no GitHub e Hugging Face, também como microsserviços NVIDIA NIM para implantação escalável.
Resumo de Dados Abertos
| Conjunto de Dados | Tamanho | Conteúdo | |---------|------|---------|| | Tokens de linguagem | 10 trilhões | Raciocínio multilíngue, codificação, segurança | | Trajetórias de robótica | 500.000 | Movimento e manipulação de robôs | | Estruturas de proteínas | 455.000 | Estruturas sintéticas para IA biomédica | | Dados de sensores de veículos | 100 TB | Condições de direção diversas | | Vídeo de direção | Mais de 1.700 horas | Casos extremos raros de 25 países |
Links para Começar
- Modelos Nemotron: developer.nvidia.com/nemotron
- Modelos Cosmos: github.com/nvidia-cosmos
- Alpamayo: developer.nvidia.com/drive/alpamayo
- Isaac GR00T: developer.nvidia.com/isaac/gr00t
Para usuários regulares, este lançamento significa melhores assistentes de voz, busca de documentos mais inteligente, desenvolvimento de medicamentos mais rápido, carros autônomos mais seguros e robôs mais capazes. Essas tecnologias serão filtradas em produtos de consumo ao longo de 2026.
A NVIDIA está apostando que, ao habilitar todo o ecossistema de IA, eles vendem mais GPUs. Com base nas empresas que já estão adotando essas tecnologias, essa aposta está valendo a pena.
