

OpenAI Lança GPT-5.2: A Primeira IA Que Supera Profissionais da Indústria
A OpenAI acabou de lançar o GPT-5.2 e os benchmarks são absolutamente impressionantes. Isso não é apenas mais uma atualização incremental. Pela primeira vez, um modelo de IA supera consistentemente profissionais da indústria em trabalho de conhecimento do mundo real.
Os Benchmarks Falam por Si
| Benchmark | GPT-5.2 Thinking | GPT-5.1 Thinking |
|---|---|---|
| GDPval (Trabalho de conhecimento) | 70.9% | 38.8% |
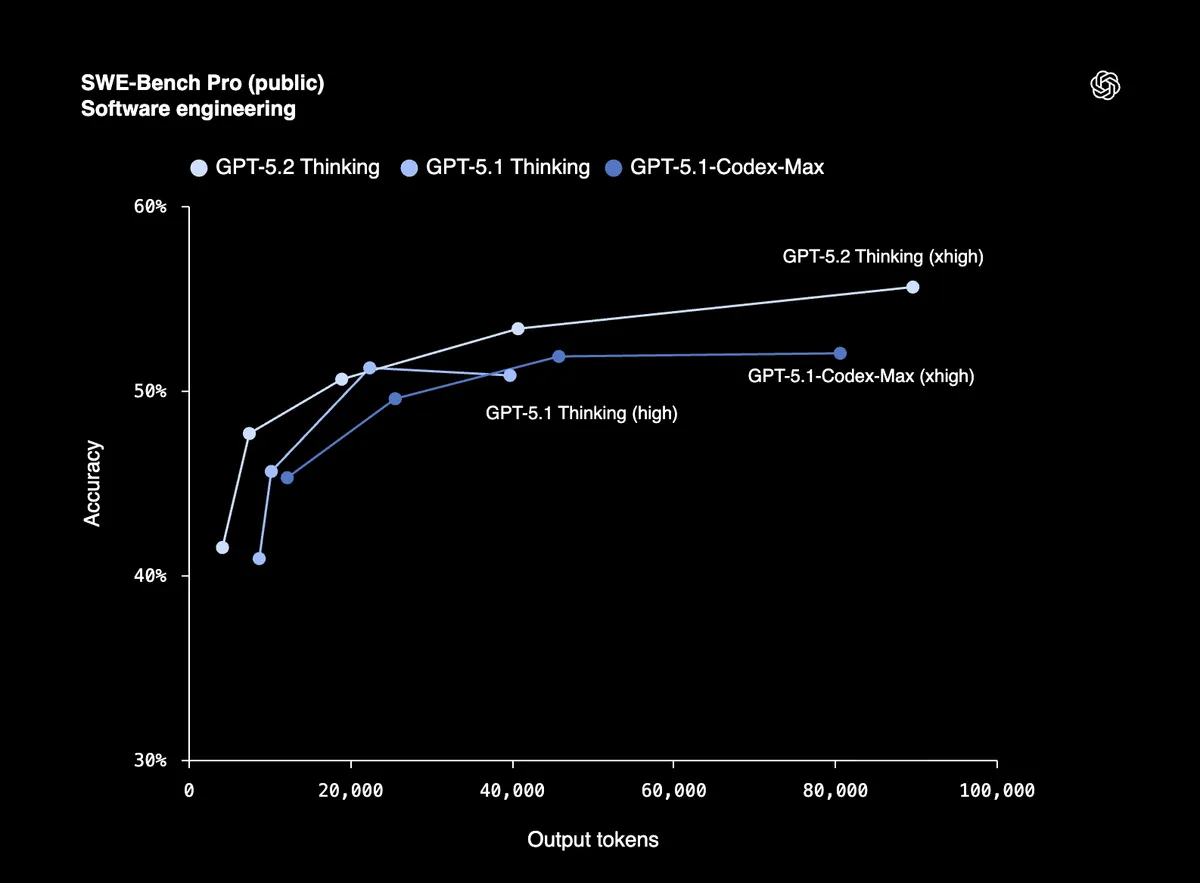
| SWE-Bench Pro (Engenharia de software) | 55.6% | 50.8% |
| SWE-Bench Verified (Engenharia de software) | 80.0% | 76.3% |
| GPQA Diamond (Questões científicas) | 92.4% | 88.1% |
| CharXiv Reasoning (Figuras científicas) | 88.7% | 80.3% |
| AIME 2025 (Matemática de competição) | 100.0% | 94.0% |
| FrontierMath Tier 1-3 (Matemática avançada) | 40.3% | 31.0% |
| FrontierMath Tier 4 (Matemática avançada) | 14.6% | 12.5% |
| ARC-AGI-1 (Raciocínio abstrato) | 86.2% | 72.8% |
| ARC-AGI-2 (Raciocínio abstrato) | 52.9% | 17.6% |
Observe esse salto no ARC-AGI-2. De 17,6% para 52,9%. Isso é uma melhoria de 3x na capacidade genuína de raciocínio abstrato em uma geração.
O Número Que Mais Importa
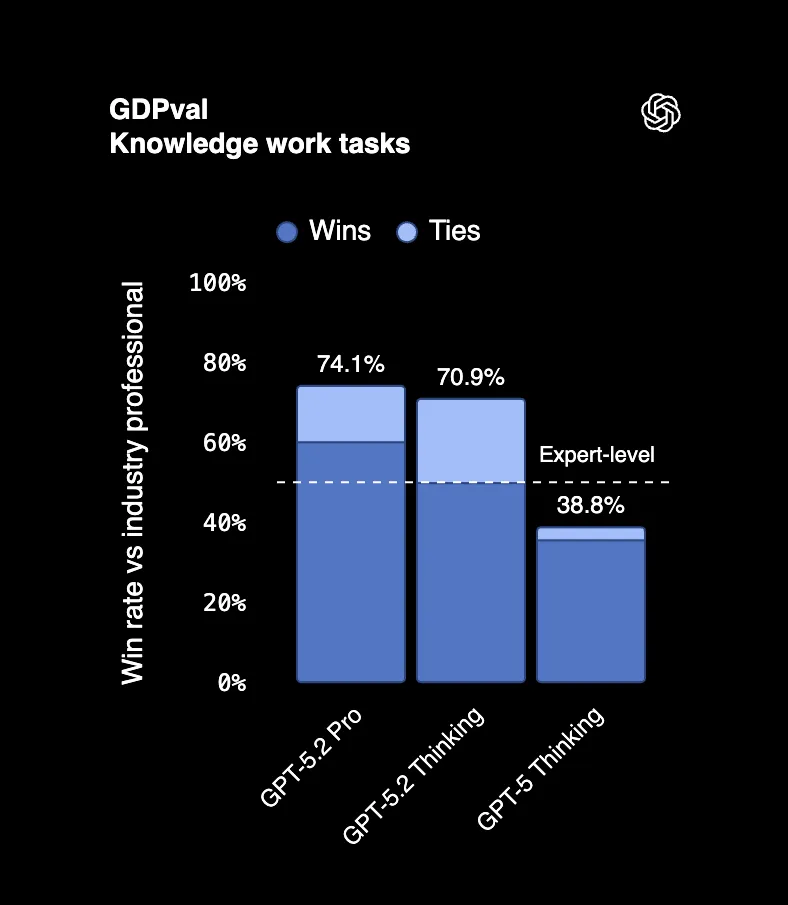
No GDPval, um benchmark que mede tarefas profissionais reais em 44 ocupações, o GPT-5.2 Thinking supera ou empata com os melhores profissionais da indústria 70,9% das vezes. Estamos falando de criar apresentações, construir planilhas, escrever relatórios, o tipo de coisa pela qual as pessoas recebem seis dígitos para fazer.
Um avaliador que revisou os resultados disse que "parece ter sido feito por uma empresa profissional com equipe". Isso não é um erro de digitação. Um resultado de IA sendo confundido com trabalho de uma equipe inteira.
E aqui está o detalhe: o GPT-5.2 produziu esses resultados a 11x a velocidade e menos de 1% do custo de profissionais especialistas.
100% em Matemática de Competição
O GPT-5.2 Thinking obteve 100% no AIME 2025, uma prestigiada competição de matemática que confunde a maioria dos humanos. Não 99%. Não 98%. Pontuação perfeita.
No FrontierMath, que testa matemática de nível especialista com a qual até matemáticos com doutorado têm dificuldade, alcançou 40,3%, acima dos 31% com o GPT-5.1.
Programação Ficou Séria
Uma pontuação de 80% no SWE-Bench Verified significa que o GPT-5.2 pode depurar código de produção de forma confiável, implementar recursos e refatorar grandes bases de código com mínima supervisão. O SWE-Bench Pro testa engenharia de software do mundo real em quatro linguagens de programação, não apenas Python.
Testadores iniciais da Windsurf, JetBrains e Warp estão chamando isso de "o maior salto para modelos GPT em codificação agêntica desde o GPT-5".
30% Menos Alucinações
Este é importante para quem usa IA profissionalmente. O GPT-5.2 Thinking produz 30% menos respostas com erros em comparação com o GPT-5.1. Para pesquisa, análise e tomada de decisões, isso é um aumento massivo de confiabilidade.
O Avanço do Contexto Longo
O GPT-5.2 é o primeiro modelo a alcançar quase 100% de precisão em tarefas de contexto longo até 256k tokens. Isso significa que você pode alimentá-lo com bases de código inteiras, contratos, artigos de pesquisa ou transcrições, e ele realmente mantém a coerência em tudo isso.
Modelos anteriores perdiam o fio da meada no meio do caminho. O GPT-5.2 não perde.
Visão Que Realmente Funciona
As taxas de erro no raciocínio de gráficos e compreensão de interface de software foram reduzidas aproximadamente pela metade. O modelo agora pode interpretar com precisão painéis, diagramas técnicos e capturas de tela, tornando-o genuinamente útil para tarefas de análise visual.

O Que Isso Significa Para Você
Se você já está pagando pelo ChatGPT Plus ou Pro, o GPT-5.2 está sendo lançado agora. O preço da API é de $1,75 por milhão de tokens de entrada e $14 por milhão de tokens de saída, com um desconto de 90% em entradas em cache.
O usuário médio do ChatGPT Enterprise já relata economizar 40 a 60 minutos diariamente. Usuários intensivos afirmam economizar mais de 10 horas por semana. Com o GPT-5.2, esses números só vão aumentar.
A Conclusão
O GPT-5.2 não é apenas melhor. Está cruzando limites que pensávamos estar a anos de distância. Pontuações perfeitas em competições de matemática. Superando profissionais em seus próprios trabalhos. Compreensão de contexto longo quase perfeita.
Estamos assistindo a lacuna entre assistência de IA e capacidade de IA se fechar em tempo real.
